
Domain, Entity
도메인
( Domain )
- 특정 기능과 관련된 속성, 기능 등을 응집화시킨 개념
- e.g.
- 도메인 이해도가 높아야 한다. = 해당 기능을 구성하는 하위 도메인에 대한 유기적 흐름 이해가 가능하다.
- 도메인 모델 = 기능적으로 군집화시켜놓은 개념으로 일반적으로는 그 도메인을 표현하는 객체를 의미하며 POJO 일수도, JPA Entity 를 도메인 모델로 사용할 수도 있다.
- 도메인 url = 하위 uri를 그루핑할 수 있는 응집화된 url
엔티티
( Entity )
- 도메인을 설명할때 말하는 엔티티 : 도메인 모델의 맥락에서
특정 주제에 대한 속성 기능을 응집화시켜놓은 도메인 모델 - DB 와 연관지어 말하는 엔티티 : DB 테이블이나 그
테이블에 매핑되는 객체
- 도메인을 설명할때 말하는 엔티티 : 도메인 모델의 맥락에서
그렇다면 도메인 맥락에서 db 엔티티와 분리되어 있다라는 말은 “나는 비즈니스 로직을 표현하기 위한 “도메인 객체”를 DB 의 엔티티와는 상관없게 표현할거야“ 라고 설명할수 있고, 그와 반대로 DB 엔티티 (e.g. JPA Entity) 를 비즈니스의 대상이 되는 도메인 모델로서 정의할 수도 있겠죠.
만약 도메인 모델 != 엔티티 라는 설계를 통해 아예 데이터베이스와 별개로 나는 비즈니스 로직을 강한 응집도를 주고, 외부의존성은 내 비즈니스 룰을 따라야 해! 라는 룰을 가져간다면 도메인영역 (핵심 비즈니스 로직) 은 엔티티를 모를테고, 이 경우 엔티티를 통해 db와 상호작용하는 datasource layer는 도메인 -> 엔티티, 엔티티 -> 도메인 의 작업을 수행하여 “내가 아는 언어” 로 변경해야 합니다.
멘토링하면서 혹은 현업에서 항상 가장 많이 받는 질문 중 하나입니다. 멀티 모듈은 어떻게 구성하는 게 좋을까요 ? 패키지는 어떻게 나누는게 좋을까요 ? 이런 질문들을 항상 받곤 하는 것 같아요. 그래서 저라면 어떤 관점에서 설계할 것인가를 적어보았습니다.
일단 기본은 앞서 발제 때, 코칭 때 설명한 것과 같이 비즈니스 로직을 보호하기 위해 Repository 를 추상화하여 비즈니스 로직이 DB 와 실제 상호작용하는 부분을 모르게 할 거예요. 그 이유는 내 비즈니스는 어떻게 어디에서 무엇을 가져오는지에 관심을 가지기보다 내가 수행해야할 기능에 집중하도록 작성하기 위해서입니다.
1 | api/ |
위와 같이 나누어 놓고 보니, 도메인 별로 강한 응집도를 가진 패키지 구조를 가지게 되었습니다. 만약 내가 User 를 개발하면서 Lecture 에 대한 정보를 사용해야 한다면, lecture 패키지만 보면 모든 것을 파악할 수 있게 됩니다.
만약 서버를 분리해야 한다 ? 하면 도메인을 뚝 떼서 가져다가 새로운 프로젝트를 구성해도 되겠죠.
하지만 우리는 일반적으로 API 서버만 작성하는 것이 아니라 관리자 ( Admin ) 애플리케이션도 같이 작성하곤 합니다. 대상은 다르지만 같은 도메인 컨텍스트를 공유하기 때문이죠.
그런 경우, 저는 뷔페식 패키지 구조를 가져가기 위해 서비스를 잘게 나누고 비즈니스 로직의 완성을 Service 가 아닌 각 애플리케이션의 UseCase 단위로 조립할 수 있도록 변경합니다.
패키지 구조
admin/ 도메인/ view/ usecase/ - ModifyLectureUseCase - GetMyApplicationsUseCase api/ 도메인/ controller dto/ (request, response models) usecase/ (Usecase = 각 비즈니스에 맞춰 component 조립) - ApplyLectureUseCase - GetLecturesUseCase domain/ 도메인/ (user, lecture, comment, ...) (Models) - Lecture - ApplicationHistory (Components) - LectureReader - LectureModifier - ApplicationManager (Repositories) - LectureReaderRepository (I/F) - LectureStoreRepository (I/F) infrastructure/ - LectureCoreReaderRepository (IMPL) - LectureCoreStoreRepository (IMPL) - LectureJpaRepository (JPA) - LectureCustomRepository (QueryDSL)// 정규화된 product 테이블 product_table { 1d: 1// 3천개 name: "토끼 티셔츠", brnadId: 1, } // 정규화된 brand 테이블 brand_table { 1d: 1, brandName: "뉴진스" 1/ NJZ }1
2
3
4
5
6
7
8
9
10
11
12
13
14
-
# 이번주 주제는 DB
## 만능은 없다
컴퓨터는 항상 문제는 2가지다. 읽기가 많아서 문제냐? 쓰기가 많아서 문제냐?
**이건 무조건 알고 가자. 만능은 없다.**
- **정규화**: 데이터 중복을 줄이고 일관성을 높임 **(쓰기 성능 ↑)**// 비정규화 product 테이블 product_table ( 1d: 1// 3천개 name: "토끼 티셔츠" brandName: "뉴진스" 1/ NJZ }1
2
3
4
5
- 장점: 쓰기 성능 높음
- 단점: 읽을때 조인, 읽기성능 저하
- **반정규화**: 일부 중복을 허용해 읽기 성능을 높임 **(읽기 성능 ↑)**MetraizedView_product mv_product { id: 1// 3천개 name: "토끼 티셔츠", brandName:"뉴진스" }1
2
3
4
- 그래서 관리는 정규화된 테이블 사용하고, 읽기 성능을 위한 뷰테이블을 생성하여 반정규화를 진행
-테이블 예시 = (주문상품번호, 상품번호, 상태) 인덱스 예시 = (주문상품번호, 상태)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
- 비정규화 테이블을 활용
- 반영되는 시간 소요됨 => 레이턴시 존재, lag이 존재.
>**참고자료**
>
>**SLO (Service Level Objective)**와 **SLI (Service Level Indicator)**는 주로 서비스 성능 및 신뢰성을 평가하기 위해 사용되는 개념들입니다. 이들은 소프트웨어 및 IT 서비스 관리에서 중요한 역할을 합니다.
>
>- **SLI (Service Level Indicator)**: 특정 서비스의 성능을 측정하기 위한 지표입니다. 예를 들어, 응답 시간, 가용성, 오류율 등이 SLI로 사용될 수 있습니다. SLI는 서비스의 품질을 수치로 표현하는 데 도움을 줍니다.
>- **SLO (Service Level Objective)**: SLI를 기반으로 설정된 목표입니다. 즉, 서비스 제공자가 달성하고자 하는 성과 기준입니다. 예를 들어, 응답 시간이 95%의 경우에 200ms를 넘지 않도록 하는 것이 SLO가 될 수 있습니다.
>
>또한, **P50**, **P95**와 같은 백분위수 개념은 SLI와 SLO의 성과를 평가하는 데 사용됩니다.
>
>- **P50 (50th Percentile)**: 전체 데이터의 중간값으로, 50%의 데이터가 이 값보다 낮거나 같습니다. 이는 평균과 비슷하지만, 데이터의 분포가 왜곡될 수 있는 경우 더 신뢰할 수 있는 지표입니다.
>- **P95 (95th Percentile)**: 전체 데이터의 95번째 백분위수로, 95%의 데이터가 이 값보다 낮다는 것을 의미합니다. 이 값은 극단적인 사례로부터의 영향을 줄여, 서비스의 성능을 보다 정확하게 평가하는 데 사용됩니다.
>
>- **DAU (Daily Active Users)**: 하루 동안 서비스나 애플리케이션을 사용한 고유 사용자 수를 나타냅니다.
>- **MAU (Monthly Active Users)**: 한 달 동안 서비스나 애플리케이션을 사용한 고유 사용자 수를 나타냅니다.
>- **WAU (Weekly Active Users)**: 일주일 동안 서비스나 애플리케이션을 사용한 고유 사용자 수를 나타냅니다.
## Transaction
- 데이터베이스의 **상태를 변화시키기 위한 일련의 작업 단위**
- 특징
- `Atomicity` ( 원자성 ) - 트랜잭션의 모든 쿼리가 DB 에 반영되거나, 모두 반영되지 않아야 한다.
- `Consistency` ( 일관성 ) - 트랜잭션의 처리 결과는 항상 일관성 있어야 한다.
- `Isolation` ( 독립성 ) - 서로 다른 트랜잭션은 서로의 연산에 개입할 수 없다.
- `Durability` ( 지속성 ) - 트랜잭션이 성공적으로 처리되었다면 그 결과는 영구 반영되어야 한다.
- 주요 기능
- `Commit` - DB 의 트랜잭션이 성공적으로 수행되었으며 이를 반영하도록 하는 명령
- `Rollback` - DB 트랜잭션에서 문제가 발생했을 때, 실행 이전 상태로 되돌리는 명령
- 트랜잭션 격리 수준
- **Uncommitted Read** ( 커밋되지 않은 읽기 )
- 다른 트랜잭션에서 커밋되지 않은 데이터에도 접근할 수 있게 해주는 격리 수준
- `DirtyRead` - 커밋되지 않은 트랜잭션에 접근해 아직 정상 반영되지 않은 데이터를 읽는 현상( 해당 데이터는 롤백되어 없어질 수도 있다 )
- **Committed Read** ( 커밋된 읽기 )
- 다른 트랜잭션에서 커밋된 데이터에만 접근할 수 있게 해주는 격리 수준
- `Non-Repeatable Read` - 하나의 트랜잭션에서 동일한 SELECT 쿼리를 실행했을 때 커밋 전의 데이터, 커밋 된 후의 데이터가 읽히면서 다른 결과가 조회되는 현상
- **Repeatable Read** ( 반복 가능한 읽기 )
- 커밋된 데이터만 읽을 수 있으며, 자신보다 빨리 수행된 트랜잭션에서 커밋한 데이터만 읽을 수 있는 격리 수준
- **MVCC** 를 통해 Undo 로그를 기반으로 동일한 데이터가 조회되도록 보장 ( Non-Repeatable Read 문제 해결 )
- 이를 지원하지 않는 DB (e.g. OracleDB ) 에서는 배타 락을 이용해 문제를 해결
- `Phantom Read` - 하나의 트랜잭션 내에서 동일한 SELECT 쿼리의 결과 레코드 수가 달라지는 현상
<aside> 💡 MySQL 에서는 Phantom Read 가 발생하지 않음 → InnoDB 엔진에 의해 `select ~ for update` 구문을 지원, Next Key Lock 형태의 배타락을 지원하기 때문
</aside>
- **Serealizable**
- 모든 트랜잭션을 순차적으로 실행시키는 격리 수준
- 트랜잭션이 서로 끼어들 수 있는 상황이 없으므로 데이터의 부정합 문제는 발생하지 않음
- 위 특성 때문에 트랜잭션이 동기적으로 처리되면서 처리속도 저하가 발생
- 트랜잭션이 개입하려는 시도 ( e.g. shared Lock 으로 조회 후 Update 하려고 하는 경우 ) 대기상태가 되므로 데드락 문제가 발생함
## DB 설계 꿀팁
**DB Table 설계 Tip**
- 테이블은 동일한 위상의 데이터 군집으로 구성한다.
- 적절한 정규화, 반정규화를 통해 데이터를 구성한다.
(정규화는 쓰기 성능을 증가시킨다. 반정규화(비정규화) 읽기성능을 증가시킨다.
- 락을 거는 특정 컬럼이 있다면 분리해내어 성능에 영향을 주지 않는 방법도 고려한다.
- 예 => 재고 테이블 분리를 통해, 락의 영향도 낮춤
- `상품`
→ `상품 정보` : 상품을 나타내는 정보들을 하나의 테이블에 응집시킨다.
→ `상품 옵션` : 각 상품 옵션은 동일한 상품 정보를 가질 것이므로 상품 정보의 Id 를 통해 연관된 상품 정보를 알 수 있도록 구성한다.
→ `상품 재고` : 재고 검증, 차감, 추가 등의 로직을 위해 배타적 Lock 을 이용한다면 상품 정보를 위한 조회에서도 영향을 받을 수도 있으므로 별도로 분리해낸다.
## DB Index, Query Optimization
**DB Index**
- 검색 속도 향상을 위해 데이터 ( row ) 를 식별 가능하도록 저장하는 객체 ( e.g. 목차 )
- `검색 속도 향상` 를 통해 `DB 부하 감소` 목적 -> full scan 방지 목적
- 특정 컬럼으로 인덱스를 설정하면, 해당 컬럼의 값을 정렬하여 데이터를 적재해두어 해당 컬럼의 조회 성능 향상
- 1~100까지의 수를 랜덤하게 펼쳐두고 30보다 작은 값을 찾기
- 1~100까지의 수를 오름차순으로 정렬된 것에서 30보다 작은 값을 찾기
- 인덱스는 조회 성능을 높일 수 있지만 아래 사항들을 고려하여 설계해야 함
- **한번에 찾을 수 있는 값** - 데이터 중복이 적은 컬럼
- **인덱스 재정렬 최소화** - 데이터 삽입, 수정이 적은 컬럼
- **인덱스의 목적은 검색** - 조회에 자주 사용되는 컬럼
- **너무 많지 않은 인덱스** - 인덱스 또한 공간을 차지함
> ⛔ **주의할 점 *** 인덱스는 저장을 위해 별도의 공간이 필요함 ( 너무 많아도 문제 )
>
> - 인덱스 조정을 위해 데이터의 삽입/수정/삭제 연산 성능이 하락
> - 그럼 언제 필요할까?
> - 데이터가 너무 많아 조건에 맞게 조회하는 데에 속도가 오래 걸리는 경우
> - 인덱스만으로 데이터를 찾을 수 있는 경우
**꼭 알아야 하는 Index**
- **`단일 Index`** - 1개 컬럼으로 구성된 Index
- **`복합 Index`** - 여러 컬럼으로 구성된 Index
→ **카디널리티가 높은 컬럼 순으로 구성해 검색 속도를 높일 수 있음**
→ 인덱스의 컬럼 순서와 조건의 조회 순서가 일치하지 않는다면 Index 이용 x
- **`Covering Index`** - 특정 쿼리를 충족시키는 데 필요한 모든 데이터를 포함하는 인덱스
→ Table Access 없이 Index Scan 만으로 원하는 데이터를 찾을 수 있음
→ Index Scan 만 발생하므로 높은 조회 성능을 가질 수 있음
→ But 너무 많은 데이터를 포함하거나 인덱스 종류가 많아지면, 그로 인한 성능 저하
### 인덱스 Column 의 기준
- 인덱스 대상 컬럼의 핵심은 **높은 카디널리티(Cardinality) (데이터의 중복이 적음)
e.g. `항해 수강생 테이블 (이름, 성별, 나이, 계좌번호, .. )`** 가 있다고 가정해봅시다. 만약 인덱스 설정을 통해 수강생 조회 성능을 높이려고 할 때, (1) 나이 → 연령대가 많이 차이나지 않으므로 많은 데이터를 걸러낼 수 없음. (2) 성별 → 50% 의 데이터만 걸러낼 수 있으므로 성별 기준 전체 조회가 아니면 유의미하지 않음. (3) 이름, 계좌번호 → 중복값이 거의 없으므로 검색 조건과 일치하지 않는 데이터 대부분을 걸러낼 수 있음.
- 우리는 데이터를 구성하고 비즈니스 로직을 위해 조회 로직을 구성할 때, 단건이 아닌 특정 조건에 부합하는 다수의 데이터를 조회하는 것에 목적을 둡니다. 그럼 **하나의 컬럼** 이 아닌 **다수의 컬럼** 에 대해 여러 조회 조건을 활용합니다. 이 경우, 아래 사항을 주의해서 설계합니다.
**여러 컬럼을 조합한 Index**
- 여러 컬럼으로 이루어진 인덱스에서는 일반적으로 **카디널리티가 높은 순** 으로 배치
```sql
CREATE INDEX IDX_P_STATUS ON ORDER_ITEM (product_id, order_status)반드시 첫번째 인덱스 조건 은 조회 조건 중 하나에 포함되어야 함
복합 Index 의 경우 조건 순서와 일치시킬수록 높은 성능을 가짐
Index 를 이용한 조회 유의사항
인덱스 컬럼의 값과 타입을 그대로 사용할 것 ( 인덱스는 컬럼의 값만 알고 있음 )
1
2
3
4
5
6
7## price 컬럼에 Index 가 적용된 경우
# 올바른 인덱스 사용
where price > 10000 / 100; // price 컬럼에 대한 Index Search
## 잘못된 인덱스 사용
where price * 100 > 10000; // price * 100 에 대한 Index XLIKE, BETWEEN, <, > 등 범위 조건의 컬럼은 Index 가 적용되나 그 뒤 컬럼은 Index 적용 x
범위 조건의 경우, Index 사용에 유의할 것
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16## Index(product_id, ordered_at, status)
where product_id = 1 and ordered_at > '2024-01-01' and status = 'PAID'
## 인덱스 저장 형상
1 2024-01-01 PAID
1 2024-01-01 DELIVERED
2 2024-01-02 PAID
3 2024-01-03 DELIVERED
3 2024-01-04 PAID
## product_id = Index
## ordered_at = Index
## status = Index X
# NOTE: datetime, id 처럼 카디널리티가 높은(데이터중복도가 낮은) 필드 이후에는
# 복합인덱스를 추가해도 의미 없는 인덱스가 될 확률이 매우 높음AND 는 ROW 를 줄이지만 OR 는 비교를 위해 ROW 를 늘리므로 Full-Scan 발생확률이 높음
WHERE 절에서
OR연산을 사용할 때는 이를 고려하자 (비추)
차라리UNION을 활용하는것이 좋다 (추천)=, IN 은 다음 컬럼도 인덱스를 사용한다.
IN 은 = 연산을 여러번 수행한 것이므로 다음 컬럼도 인덱스를 태울 수 있음.
Covering Index
- 앞서 배운 것처럼 조회하고자 하는 모든 컬럼이 조회 대상, 조회 조건에 포함된다면 데이터를 찾기 위해 ROW 에 접근할 필요가 없으므로 높은 성능의 조회를 달성할 수 있음
- 인덱스는 Read 연산의 효율을 높이지만 ! CUD 연산에서는 오버헤드가 발생한다고?!
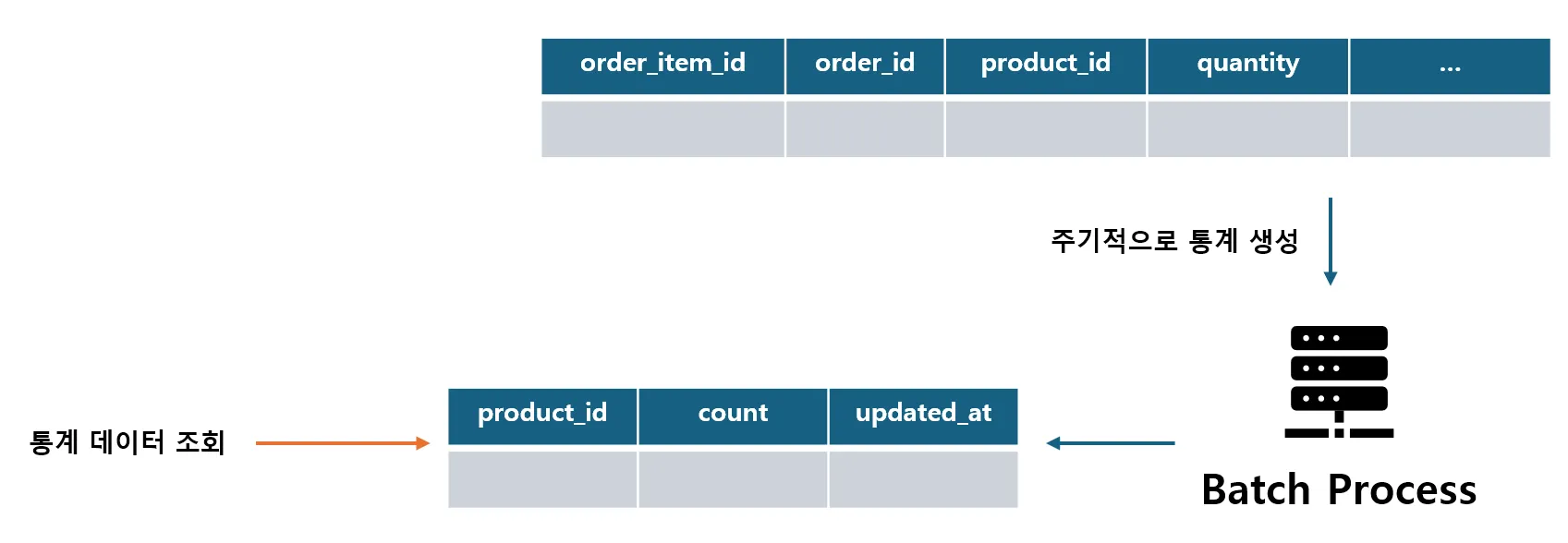
Sync Schedule Strategy
- 전략적으로 실시간 업데이트나 값을 조회하는 것이 아닌
통계데이터를 활용하는 방법도 있음 - 앞서 말했던 자주 삽입, 수정되는 데이터에 대해 Index 를 적용할 경우 “배보다 배꼽이 커지는” 문제가 발생할 수 있음 ( 인덱스 또한 공간을 차지하므로 )
Sync Schedule
실시간성과 정합성의 Trade-Off 를 극복하기 위해 DB I/O 를 줄이고 언젠가 정합성이 맞아 떨어지는 환경을 구성하는 전략
주기적으로 통계 데이터를 Batch Process 를 통해 취합하고 Sync 를 맞추는 테이블을 생성
- 비정규화현상과 유사
통계 데이터를 조회할 땐 통계용 테이블만을 조회 ( 조회 연산 성능 향상 )
1
(유사 패턴 keyword: [materialized view pattern](<https://youtu.be/8OFTB57G9IU?t=1294>))
반드시 동시성 테스트 시 ADR 작성하기
https://yonikim.tistory.com/158
- 동시성 문제를 해결은 하지않아도되지만 ADR 보고,
- 동시성 테스트 작성후 실패를 일어나게 하면됨.
백엔드 8기 4주차 평일 Q&A
질문1
- 통합테스트시 파사드부터 진행하면될까요?
답변
- 파사드는 사실상 통합테스트가 필요없다. -> 파사드의 비즈니스 로직없으니까.
- 도메인 주도 설계를 했다면, 각 도메인 서비스와 도메인 모델의 비즈니스 로직들이 각자의 책임을 이미 테스트하고있기때문이다
- 파사드에서 조립했는데, 잘못될 확률은 극히 낮다.
질문2
- JPA연관관계 안쓰고 Long userId처럼 쓰는분, 어떤분은 @OneToMany, @ManyToOne 사용한 연관관계 사용. 그리고 라이프사이클 같은 도메인끼리 사용?
답변2
- 네, 라이프사이클이 완전히 동일한 경우에만, 연관관계를 매핑하며, 나머지는 id값만 해놓습니다.
- 연관관계 사용 케이스 : Order-OrderItem 서로 생성될려면 서로 필요함
- 연관관계 사용 안하는 케이스 : User-coupon은 도메인, 생명주기가 다름. Coupon은 단순한 userId값으로만 들고있다고생각함.
- MSA로 분리될때, 모든 연관관계를 처리하는것은 비추합니다.
질문3
- 실무에서는 db에 fk를 안거는데, 왜그런건가요?
답변3
- 물리적 fk를 걸면, 데이터를 이관하거나 삭제하기가 매우 힘들어지고, 동일 트랜잭션에서 부모 자식에서 fk락이 걸린다.
- 논리적 fk는 많이건다
질문4
- 보고서 작서잇, 인덱스 적용후 쿼리 테스트 1만건? , 쿼리 튜닝 결과에 대해서는
쿼리 실행 계획 첨부 후 인덱스가 잘 탓는지, 실행 시간 줄었는지 검토?
답변4
- 보고서 작성 전에, 해당 service가 왜 동시성 이슈가 있으며, 어떤 식으로 해결하려고했고,
- DB 옵티마이져 입장에서는 table의 카디널리티가 있는 테스트 데이터가 있어야 테스트 데이터 의미가 존재하며,
- 어떤 테스트 기법?
- 어떤 테스트 도구들을 활용해서 테스트 해볼껀지?
- Grafana k6를 활용하여 부하 테스트 한번해봐라
- 어떤 것을 검증할것인지?
질문5
- coupon과 product가있는데, 고객사가 특정 product에 coupon을 사용할수없게 하는 기능을 추가해달라고했다. 과연 product 테이블에 can_use_coupon: boolean을 설계하는것이 좋은것인가? 아니라면 어떤점이 안좋고, 더 좋은 방법은 없나?
답변5
- ??
질문6
- DB테이블에는 외래 키 제약조건을 걸지 않고, 애플리케이션 레벨에서 연관관계를 맺어도 괜찮을까요?
답변6
- 네 꼭 그렇게하세요
질문7
- 검색쿼리 최적화방법?
답변 7
- 엘라스틱 서치 사용중
질문 8
- CQRS 분리
답변 8
- Repository 에서 save, find등으로 이미 메서드명으로 분리되는데 구지?
- 물론 Reader에서 캐시, 슬레이브 DB를 바라보고, Command에서는 마스터DB를 바라보면 인프라에서 분리하는것은 좋아보임
- 가장 어려웟던 코드 -> 광고가 3,3,3 9개가 노출, 첫번째부터 맨끝까지 가격이 달라야함. 위에잇는 광고는 돈많이, 마지막 광고는 적게, 3번째 상품이 제일 클릭률이 높앗고, 이를 옵티마이즈, 오른쪽 3번째 등등 조건을 가중평균 등등 실시간 옵티마이즈 계속 실시간성, 조회성능이 좋아..