
Kafka(카프카) 개요 및 예제
Created Time: August 16, 2022 12:41 PM
Last Edited Time: December 23, 2022 5:19 PM
References: https://velog.io/@kero88/Apache-Kafka
https://err0rcode7.github.io/backend/2021/06/19/%EB%A9%94%EC%8B%9C%EC%A7%80-%ED%81%90%EC%99%80-%EC%A2%85%EB%A5%98-%EA%B7%B8%EB%A6%AC%EA%B3%A0-%EB%B9%84%EA%B5%90.html
https://always-kimkim.tistory.com/entry/kafka101-message-topic-partition
https://webfirewood.tistory.com/153
https://jyeonth.tistory.com/30
Tags: Java, Kafka, Spring, Computer, Web
구현후 5번만 더 읽어보자
아파치 카프카
아파치 카프카는 웹사이트, 어플리케이션, 센서 등에 취합한 데이터를 스트림 파이프라인을 통해서 실시간으로 관리하고 보내기 위한 분산 스트리밍 플랫폼이다. 데이터를 생성하는 어플리케이션과 데이터를 소비하는 어플리케이션 간의 중재자 역할을 함으로써 데이터의 전송 제어, 처리, 관리 역할을 한다. 즉, 카프카는 플랫폼에 서비스를 연결하여 다양한 서비스에서 나오는 데이터 흐름을 실시간으로 제어하는 서비스의 중추역할을 하는 플랫폼이다.
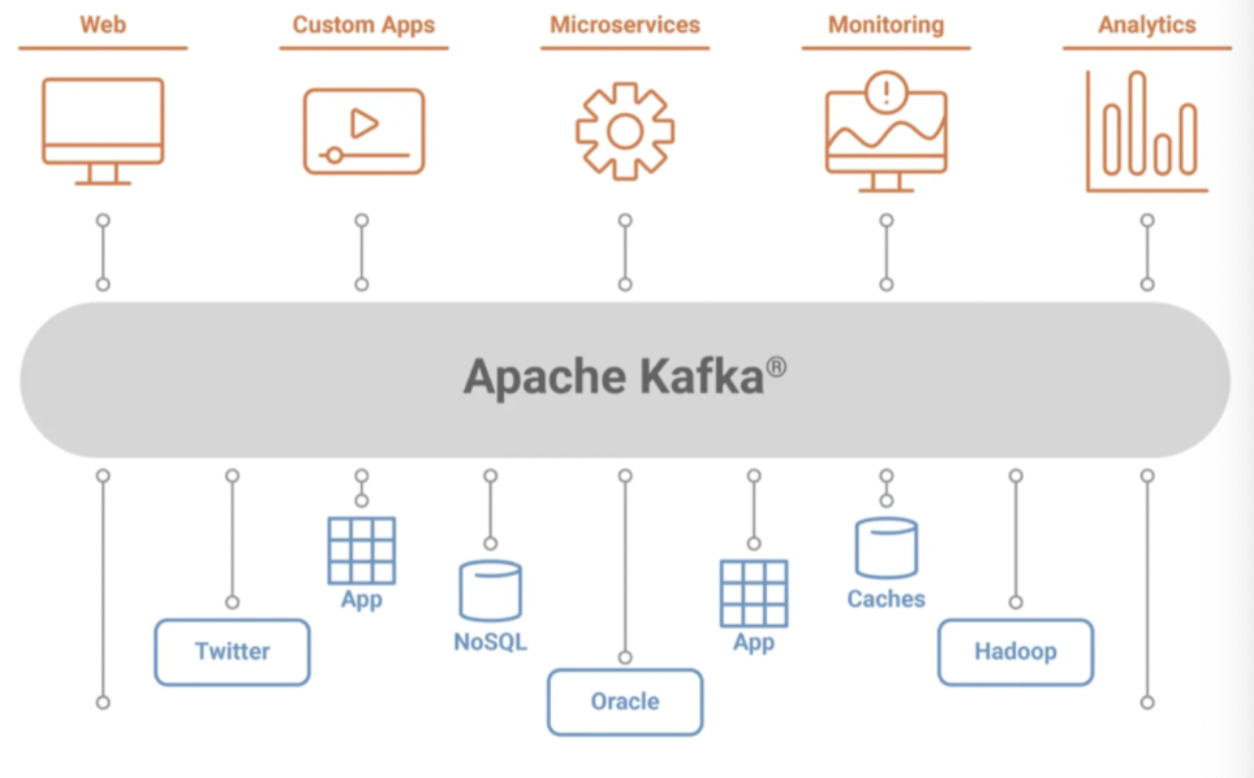
전체 구조
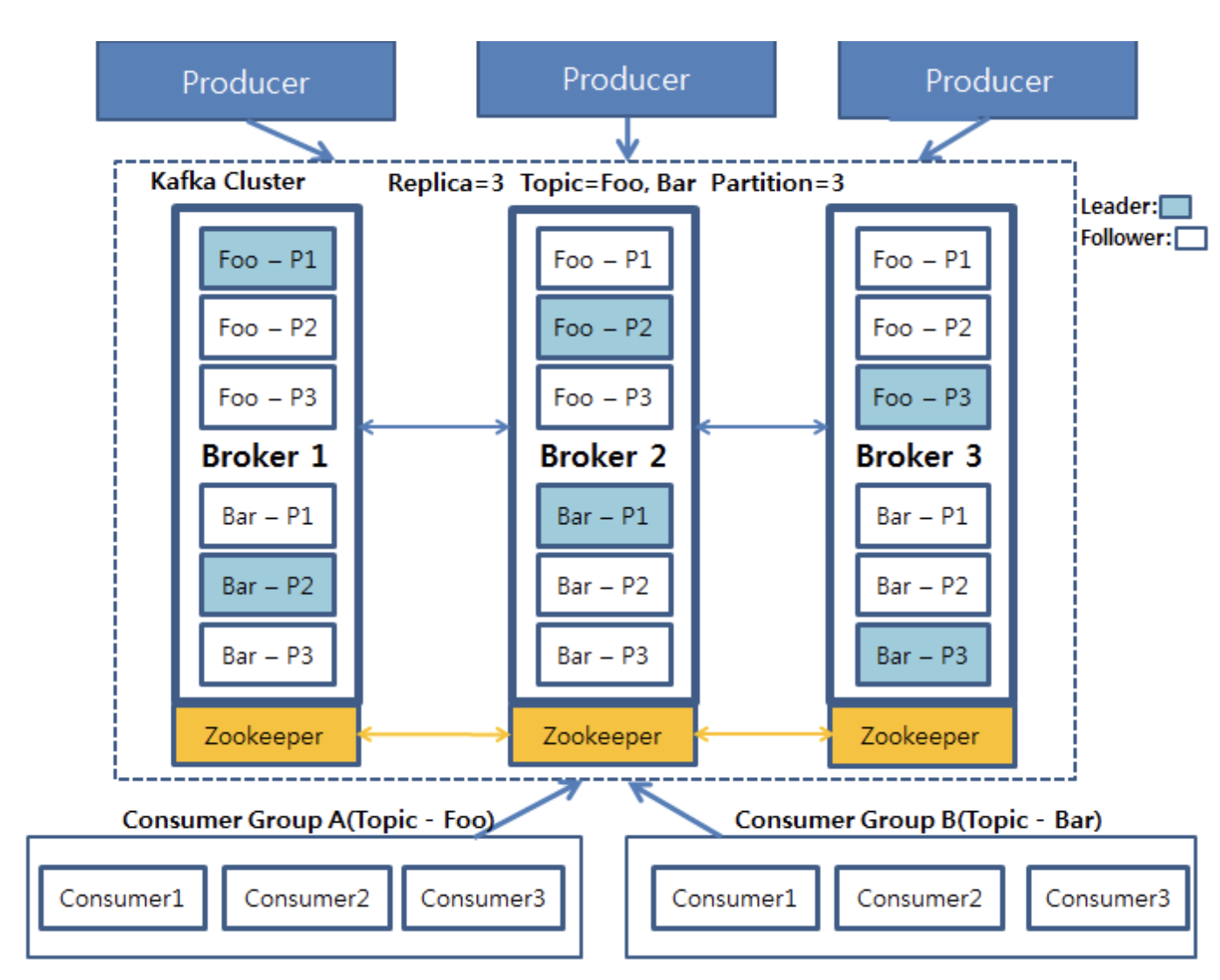
구성요소
- Producer
- Consumer
- Broker
카프카 메시지와 토픽과 파티션
카프카의 요소인 토픽과 파티션의 개념을 보자
카프카의 메세지
카프카의 메시지는 Key(키)와 Value(값)로 구성됩니다. 먼저, 메시지의 키는 해당 메시지가 카프카 브로커 내부에 저장될 때, 저장되는 위치와 관련된 요소입니다. 프로듀서가 메시지를 브로커로 전달할 때, 프로듀서 내부의 파티셔너(Partitioner)가 저장 위치를 결정하는데, 이때 키의 값을 이용하여 연산하고 그 결과에 따라 저장되는 위치를 결정합니다. (즉, 키가 같다면 동일한 토픽+파티션에 들어갈것이므로 순서보장가능)(키 값이없다면, 보장못함)
메시지의 값은 메시지가 전달하고자 하는 내용물을 의미합니다. 값은 단순한 문자열이 될 수도 있고, JSON이나 특정 객체가 될 수 있습니다. 참고로 이렇게 다양한 타입의 값을 보낼 수 있는 것은 브로커를 통해 메시지가 발행되거나 소비될 때, 메시지 전체가 직렬화/역직렬화되기 때문입니다.
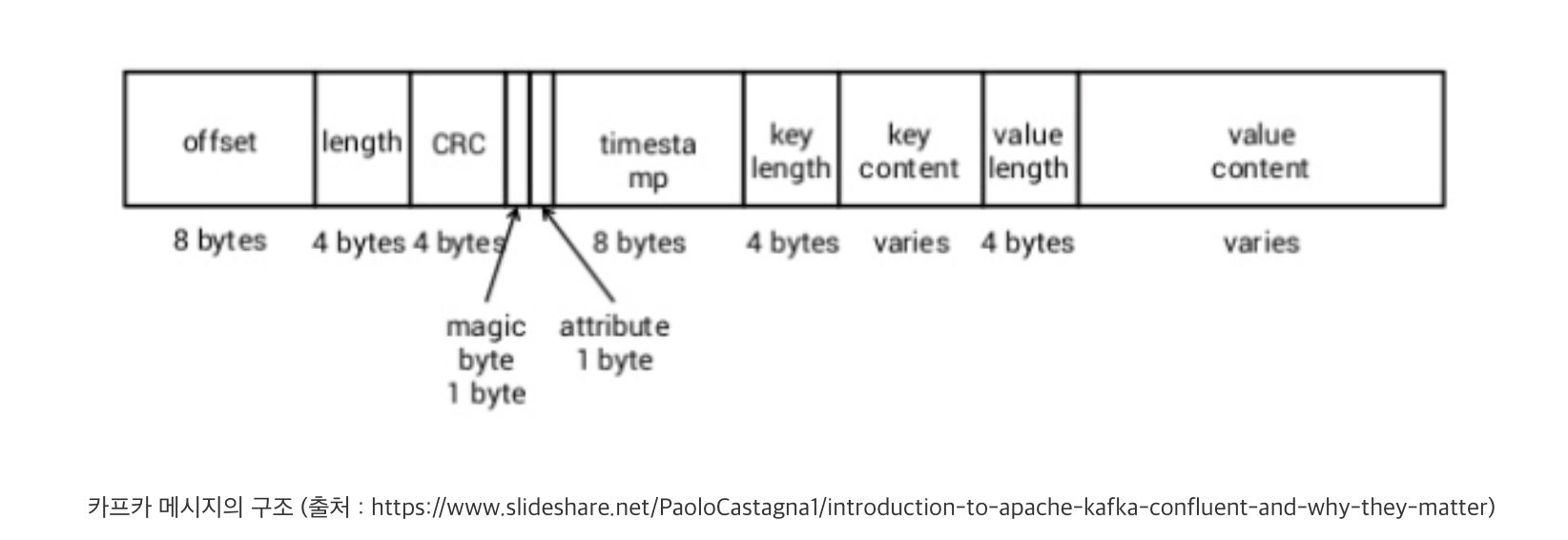 메시지의 키와 값은 다양한 타입이 될 수 있지만, 특정한 구조인 스키마(schema)를 가집니다. 카프카 메시지의 스키마는 데이터베이스의 테이블 스키마와 유사한 개념입니다. 이는 프로듀서가 발행하고 컨슈머가 소비할 때 메시지를 적절하게 처리하기 위해 필요합니다. 예를 들어, 프로듀서가 내용(값)이 JSON 형태인 메시지를 발행할 때, 해당 메시지를 소비하는 컨슈머는 프로듀서가 생산한 JSON의 구조를 예상하고, 그에 맞게 메시지를 처리하려고 합니다. 이때 만약 프로듀서와 컨슈머가 메시지에 대한 서로 다른 스키마를 가지고 있다면, 정상적인 처리를 할 수 없습니다. 이처럼 스키마는 카프카 개발, 운영에서 굉장히 중요한 역할을 담당합니다. 스키마 관리에 관한 더욱 자세한 이야기는 이후 스키마 레지스트리 부분에서 정리하겠습니다.
메시지의 키와 값은 다양한 타입이 될 수 있지만, 특정한 구조인 스키마(schema)를 가집니다. 카프카 메시지의 스키마는 데이터베이스의 테이블 스키마와 유사한 개념입니다. 이는 프로듀서가 발행하고 컨슈머가 소비할 때 메시지를 적절하게 처리하기 위해 필요합니다. 예를 들어, 프로듀서가 내용(값)이 JSON 형태인 메시지를 발행할 때, 해당 메시지를 소비하는 컨슈머는 프로듀서가 생산한 JSON의 구조를 예상하고, 그에 맞게 메시지를 처리하려고 합니다. 이때 만약 프로듀서와 컨슈머가 메시지에 대한 서로 다른 스키마를 가지고 있다면, 정상적인 처리를 할 수 없습니다. 이처럼 스키마는 카프카 개발, 운영에서 굉장히 중요한 역할을 담당합니다. 스키마 관리에 관한 더욱 자세한 이야기는 이후 스키마 레지스트리 부분에서 정리하겠습니다.
카프카의 토픽
카프카의 토픽(Topic)은 메시지를 구분하는 논리적인 단위로, 동일한 토픽의 메시지들은 논리적으로 같은 문맥(context)을 가집니다. 예를 들어, 주문에 관한 내용을 담고 있는 메시지를 발행하고, 소비하기 위해서 우리는 order라는 토픽을 생성하고 이 토픽을 기준으로 메시지를 발행, 소비할 수 있습니다.
이처럼 토픽은 논리적인 단위이자 메시지 흐름의 단위이기도 합니다. 그렇기 때문에 토픽을 설계할 때는 메시지의 논리적인 구분을 명확하게 해야 합니다.
카프카의 파티션
논리적인 단위인 카프카 토픽을 기준으로 발행되는 메시지들은 브로커 내부의 물리적인 단위인 카프카 파티션(Partition)으로 나뉩니다. 즉, 모든 토픽은 각각 대응하는 하나 이상의 파티션이 브로커에 구성되고, 발행되는 토픽 메시지들은 파티션들에 나뉘어 저장됩니다.
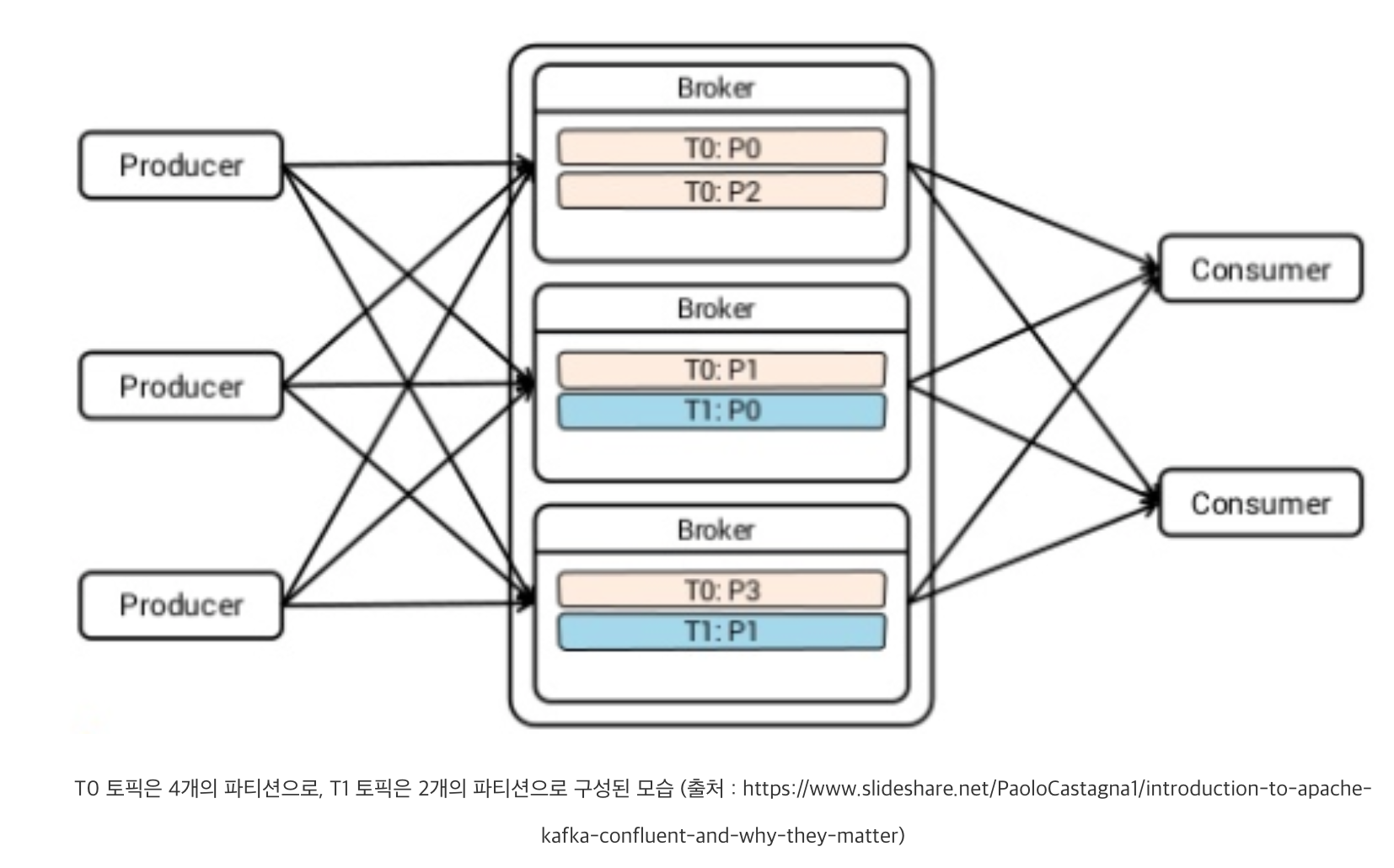
이렇게 하나의 토픽에 대하여 여러 파티션을 구성하는 가장 큰 이유는 분산 처리를 통한 성능 향상에 있습니다. 카프카는 하나의 토픽에 대해 여러 프로듀서가 발행할 수 있고, 여러 컨슈머가 구독할 수 있습니다. 그렇기 때문에 토픽을 하나의 파티션으로 구성하면, 무수한 발행-구독 요청을 하나의 파티션이 처리해야 합니다. 물론 카프카는 하나의 파티션만으로도 충분한 성능을 발휘할 수 있지만, 일반적으로 2개 이상의 파티션을 서로 다른 브로커에 병렬 구성하여 요청의 부하를 분산시켜 줍니다. 이에 따라 자연스럽게 해당 토픽에 관한 성능도 향상시킬 수 있습니다.
이외에도 파티션의 가장 큰 특징은 하나의 파티션 내에서는 메시지 순서가 보장되는 것입니다. 즉, 파티션은 메시지 순서 보장의 단위로써, 각 파티션의 메시지는 발행되는 순서대로 구독할 수 있습니다. 따라서 하나의 토픽이 여러 파티션으로 구성되는 경우, 토픽 단위의 메시지 순서는 보장할 수 없습니다. 이는 파티션 내부에서의 순서는 보장되지만 파티션 간의 순서는 보장되지 않기 때문입니다.
파티션 복제
하나의 토픽은 하나 이상의 파티션으로 구성됩니다. 여기에서 나아가 카프카는 서비스 안정성과 장애 수용(Fault-Tolerance)에 관한 요소로 파티션의 복제(Replica) 기능을 제공합니다.
하나의 파티션은 1개의 리더 레플리카와 그 외 0개 이상의 팔로어 레플리카로 구성됩니다. 리더 레플리카는 파티션의 모든 쓰기, 읽기 작업을 담당합니다. 반대로 팔로어 레플리카는 리더 레플리카로 쓰인 메시지들을 그대로 복제하고, 만약 리더 레플리카에 장애가 발생하는 경우, 리더 자리를 승계받을 준비를 합니다. 참고로 승계받을 준비가 된 즉, 리더 레플리카의 메시지를 적절하게 복제하여 리더 레플리카와 동기화된 레플리카들의 그룹을 ISR(In-Sync Replica)라고 합니다.
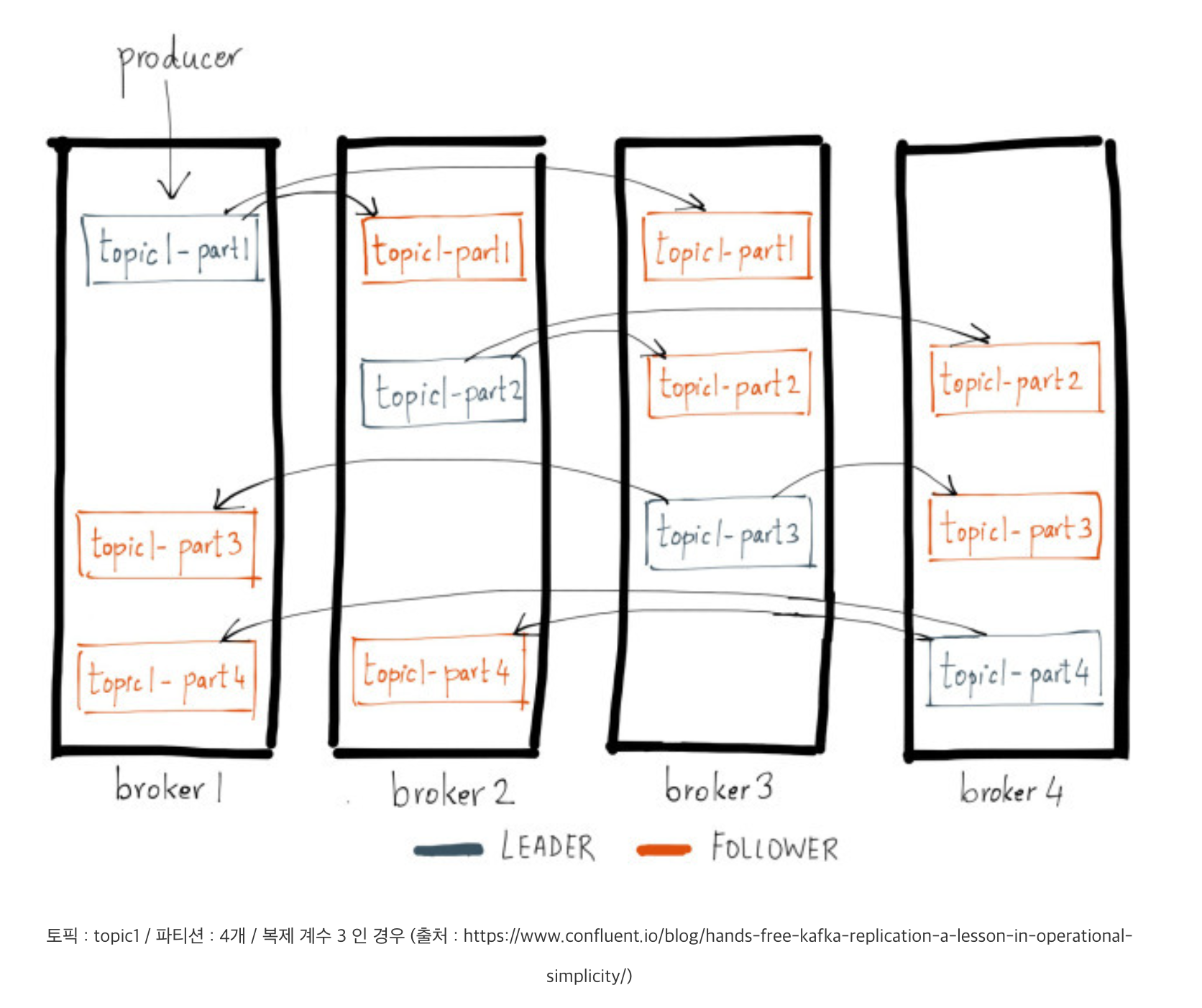
파티션의 레플리카 수는 복제 계수(Replication factor)를 통해 결정되는데, 만약 복제 계수가 1이라면 파티션은 리더 레플리카로만 구성됩니다. 이때, 파티션과 리더 레플리카는 별개인 것이 아니라 동일한 것으로 볼 수 있습니다. 즉, 일반적으로 말하는 ‘물리적인 파티션’은 리더 레플리카를 이야기한다고 할 수 있습니다. 나아가 복제 계수가 2개 이상이라면 해당 파티션은 1개의 리더 레플리카와 1개 이상의 팔로어 레플리카로 구성됩니다. 이 경우 모든 레플리카들은 서로 다른 브로커에 구성됩니다. 만약 같은 파티션의 레플리카가 동일한 브로커에 구성되는 경우에는 에러가 발생합니다.
이처럼 파티션의 레플리카들은 언제 발생할지 모르는 장애에 대비하여 데이터 유실을 방지하고, 지속적인 서비스를 제공하기 위해 구성됩니다.
요약
토픽은 논리적인 단위이고 파티션은 물리적인 단위, 나아가 파티션은 하나 이상의 레플리카로 구성되는 것은 매우 중요한 내용입니다.
카프카 프로듀서
프로듀서는 카프카 프로듀서 API와 그것으로 구성된 애플리케이션을 말한다.
프로듀서는 브로커에 특정 토픽(혹은 파티션 영역까지)을 지정하여 메시지를 전달하는 역할을 한다. (가장 중요한 토픽과 파티션이 이때 정해진다)
메시지 구조

- 토픽
- 토픽 중 특정 파티션 위치
- 메시지 생성 시간
- 메시지 키
- 메시지 값
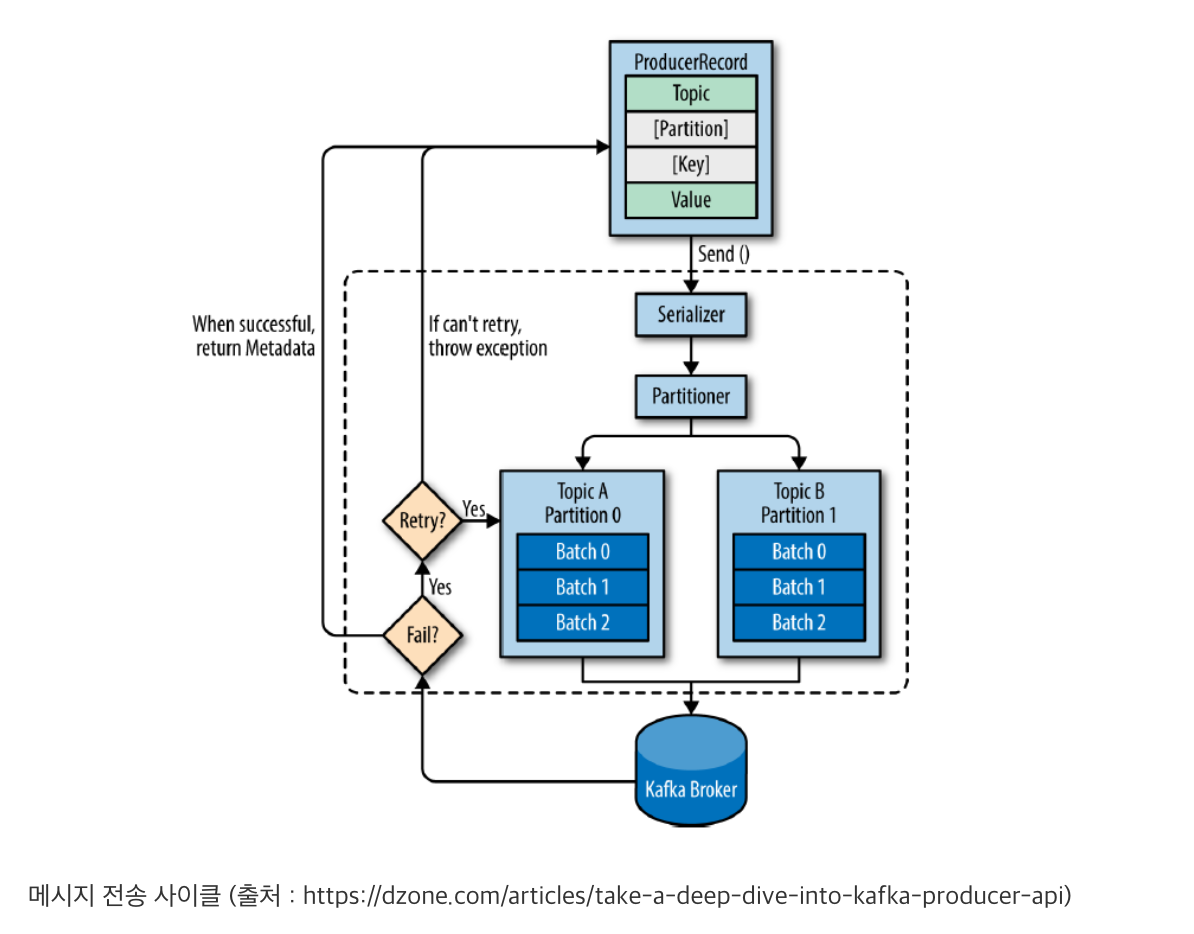
프로듀서 구조와 메시지 전달 과정
4가지 과정을 통해 메세지를 브로커에 전달한다.
브로커에 메시지를 전송할수있도록 변환 + 필요한 값을 지정해주는 과정
- 직렬화 (Serializer)
- 파티셔닝 (Partitioner)
- 압축 (Compression)
- 메시지 배치 (Record Accumulator)
- 전달 (Sender)
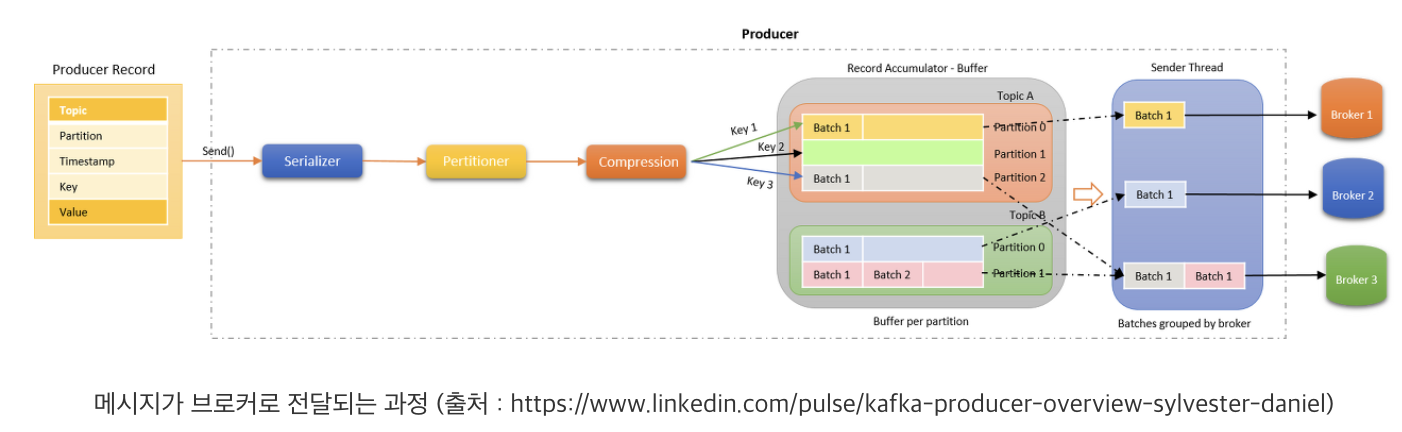
프로듀서는 먼저, 전달 요청받은 메시지를 직렬화합니다. 직렬화(Serialization)는 Serializer가 지정된 설정을 통해 처리하며,메시지의 키와 값은 바이트 뭉치 형태로 변환됩니다. 직렬화 과정을 마친 메시지는 Partitioner를 통해 토픽의 어떤 파티션에 저장될지 결정됩니다. 이 과정을 파티셔닝(Partitioning)이라 말합니다. Partitioner는 정의된 로직에 따라 파티셔닝을 진행하는데, 별도의 Partitioner 설정을 하지 않으면 Round Robbin 형태로 파티셔닝을 합니다. 즉, 파티션들에게 골고루 전달할 수 있도록 파티셔닝을 합니다. 다만, 이 과정은 메시지 전달 요청에 파티션이 지정되지 않았을 경우에만 진행됩니다. 따라서 메시지 전달 요청에 특정 파티션이 지정되었을 경우에는 별도의 파티셔닝 없이 해당 파티션으로 전달되도록 지정됩니다.
만약 메시지 압축이 설정되었다면, 설정된 포맷에 맞춰 메시지를 압축합니다. 압축된 메시지는 브로커로 빠르게 전달할 수 있을뿐더러, 브로커 내부에서 빠른 복제가 가능하도록 합니다.
파티셔닝과 압축을 마친 후, 프로듀서는 메시지를 TCP 프로토콜을 통해 브로커 리더 파티션으로 전송합니다. 하지만 메시지마다 매번 네트워크를 통해 전달하는 것은 비효율적입니다. 네트워크 전송은 매우 무거운 처리이기 때문입니다. 그래서 프로듀서는 지정된 만큼 메시지를 저장했다가 한 번에 브로커로 전달합니다. 이 과정은 프로듀서 내부의 Record Accumulator(RA)가 담당하여 처리합니다. RA(Buffer)는 각 토픽 파티션에 대응하는 배치 큐(Batch Queue)를 구성하고 메시지들을 레코드 배치(Record Batch) 형태로 묶어 큐에 저장합니다.
각 배치 큐에 저장된 레코드 배치들은 때가 되면 각각 브로커에 전달됩니다. 이 과정은 Sender가 처리합니다. Sender는 스레드 형태로 구성되며,관리자가 설정한 특정 조건에 만족한 레코드 배치를 브로커로 전송합니다. 이때, Sender 스레드는 네트워크 비용을 줄이기 위해piggyback 방식으로 조건을 만족하지 않은 다른 레코드 배치를 조건을 만족한 것과 함께 브로커로 전송합니다.
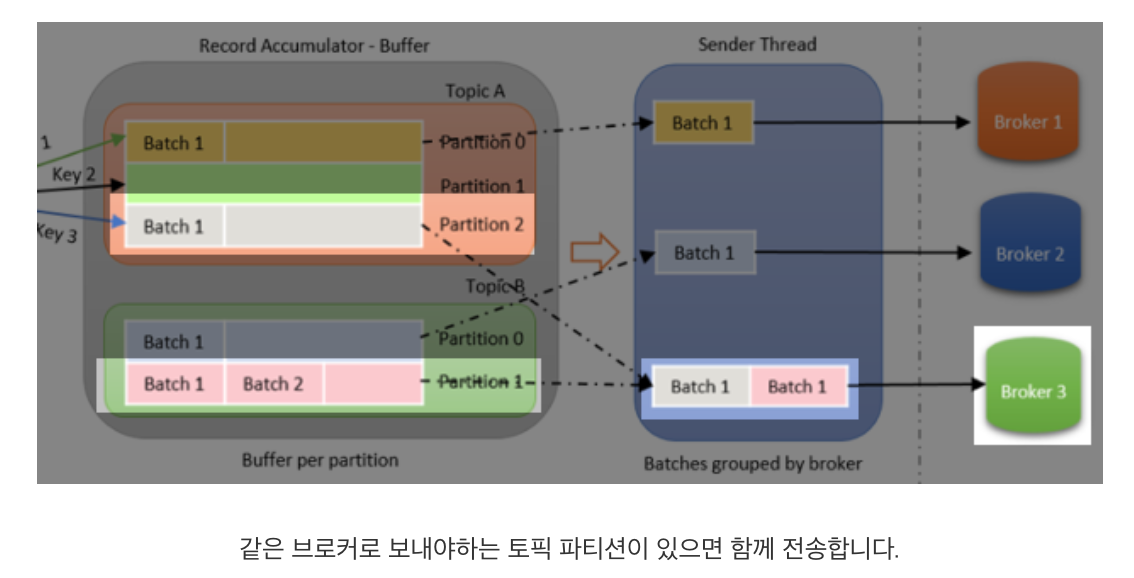
Piggyback이란 ‘등 뒤에 업다’라는 뜻입니다. 위 그림을 예로 들면, 토픽 B의 파티션 1(B_1)의 큐에 레코드 배치가 전송할 조건을 만족했다고 가정하면, Sender는 해당 레코드 배치를 가져와 3번 브로커로 전송할 준비를 합니다. 이때,토픽 A의 파티션 2(A_2)가 전송 조건을 만족하지 않았더라도 같은 3번 브로커에 전송돼야 하므로, Sender는 A_2 레코드 배치를 업어 한번에 3번 브로커로 전송합니다. 이로 인해 자연스럽게 네트워크 비용을 줄일 수 있습니다.
(추가설명: 토픽B 파티션1의 배치 큐를 보면 레코드 배치1, 레코드 배치2가있는데, 이때, Batch1만 RA에서 sender thread로 이동하는것을 보면, 이것이 토픽은 논리적인것이라 순서가 보장안되지만, 파티션에서는 배치 큐로 구성되며, 전송시 배치 큐에서 하나만 가져감.>> 각 파티션은 순서 보장가능!)(???)
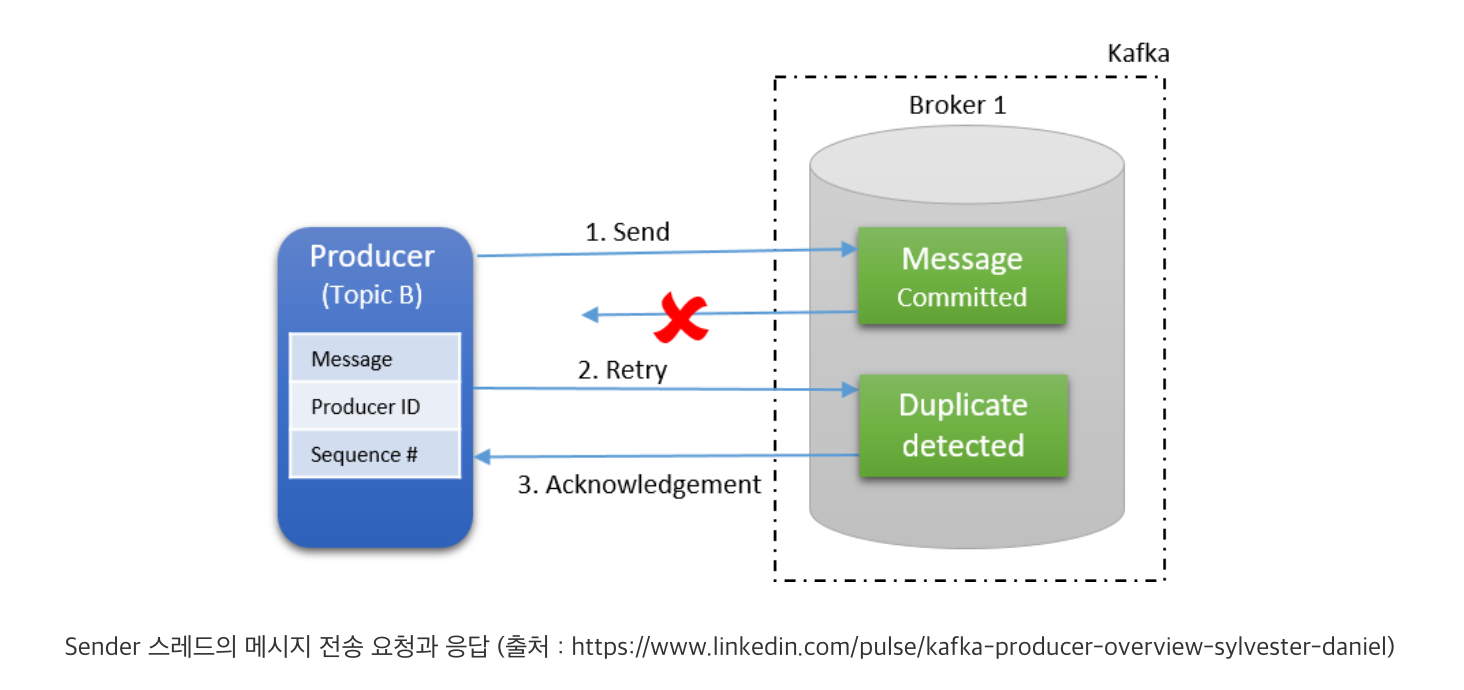
브로커에 네트워크 전송 요청을 보낸 Sender는 설정 값에 따라 브로커의 응답을 기다리거나 혹은 기다리지 않습니다. 만약 응답을 기다리지 않는 설정인 경우, 메시지 전송에 대한 과정이 마쳐집니다. 하지만 응답을 기다리는 경우, 메시지 전송 성공 여부를 응답으로 받습니다. 이때, 브로커에서 메시지 전송이 실패한 경우에는 설정 값에 따라 재시도를 시도합니다. 재시도 횟수를 초과한 경우에는 예외를 뱉어냅니다. 반대로 성공한 경우에는 메시지가 저장된 정보(메타데이터)를 반환합니다. 메타데이터는 메시지가 저장된 토픽, 파티션, 오프셋, 타임스탬프 정보를 가지고 있습니다.
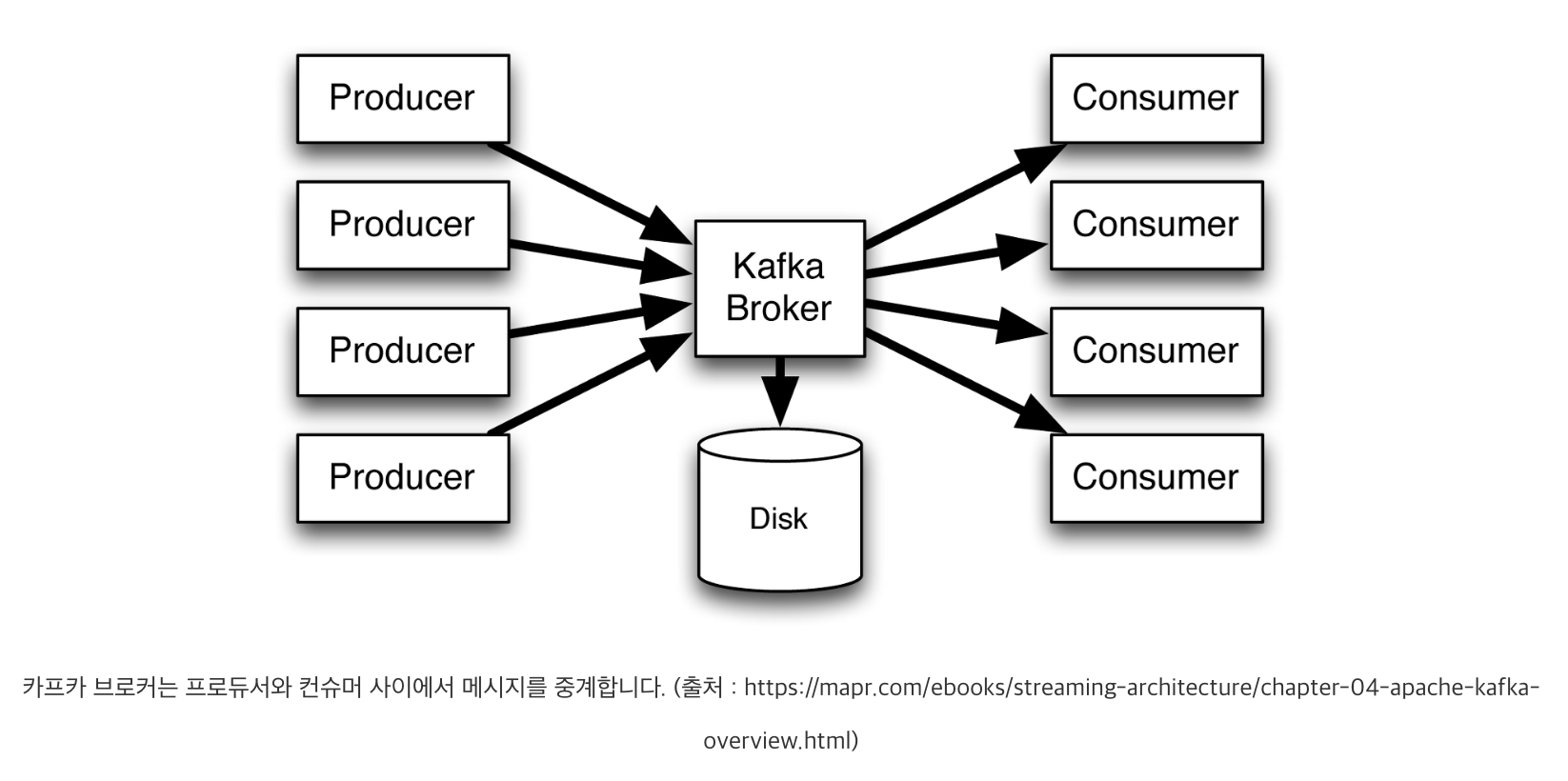
카프카 브로커
카프카는 메시지를 생산하는 프로듀서와 소비하는 컨슈머, 그리고 그 사이에서 메시지를 저장, 전달하는 브로커(Broker)로 구성됩니다. 이번 글은 카프카의 중추인 브로커에 대해 전반적으로 설명합니다.
1. 카프카 브로커
카프카 브로커는 일반적으로 ‘카프카’라고 불리는 시스템을 말합니다. 프로듀서와 컨슈머는 별도의 애플리케이션으로 구성되는 반면, 브로커는 카프카 자체이기 때문입니다. 따라서 ‘카프카를 구성한다’ 혹은 ‘카프카를 통해 메시지를 전달한다’에서 카프카는 브로커를 의미합니다.
2. 카프카(브로커) 클러스터 구성
브로커는 한 대 이상의 노드로 클러스터를 구성할 수 있습니다. 하지만 현재(2020.03.28 v2.4.1)는 브로커들로만 클러스터를 구성할 수 없습니다. 브로커의 여러 가지 메타 정보를 저장 관리해주는 주키퍼(Zookeeper)가 필요하기 때문입니다. 따라서, 카프카를 구성할 때는 한 대 이상의 주키퍼로 구성된 주키퍼 클러스터와 한 대 이상의 브로커로 구성된 브로커(=카프카) 클러스터로 구성됩니다.
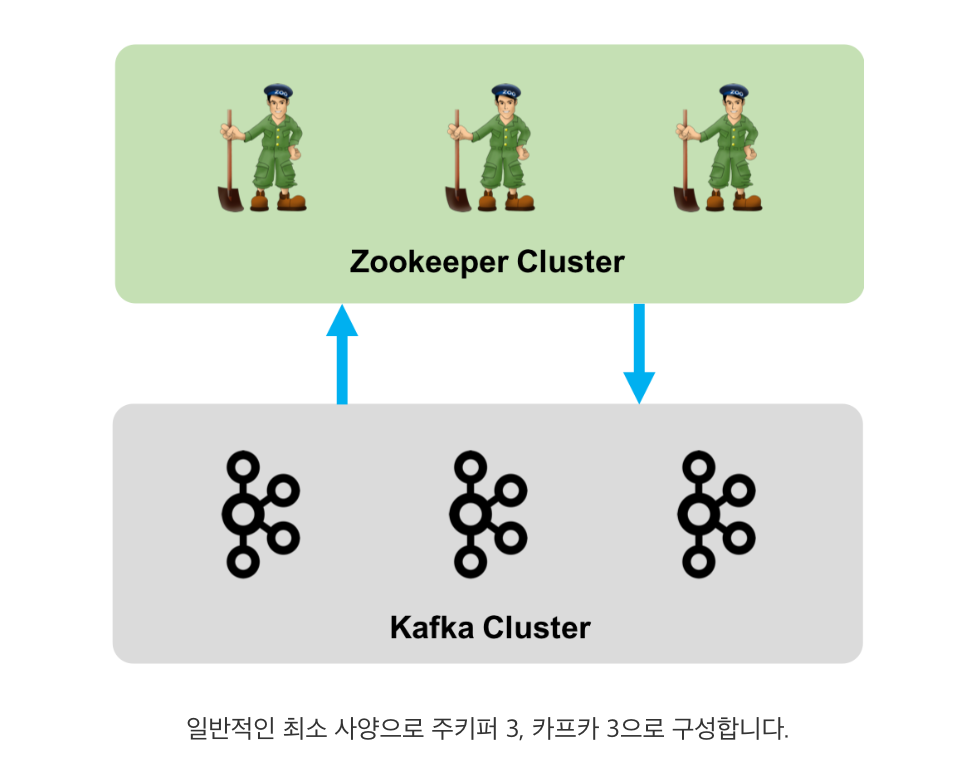
주키퍼
주키퍼는 현재 카프카에 필수적이기에 간단히 설명하고 넘어가겠습니다. 주키퍼는 아파치 프로젝트 중 하나로 하둡 에코 시스템을 구성합니다. 주 역할은 분산 시스템의 메타 정보를 관리하고, 필요시에는 분산 시스템의 마스터를 선출합니다. 예를 들면, 카프카 클러스터를 구성하면 주키퍼에는 카프카 클러스터의 식별 정보부터 현재 살아있는 브로커 정보, 나아가 권한 정보 등이 저장됩니다. 또한, 카프카 브로커들 중 일종의 지휘자 역할을 하는 컨트롤러(Controller) 브로커를 뽑는 역할을 담당합니다.
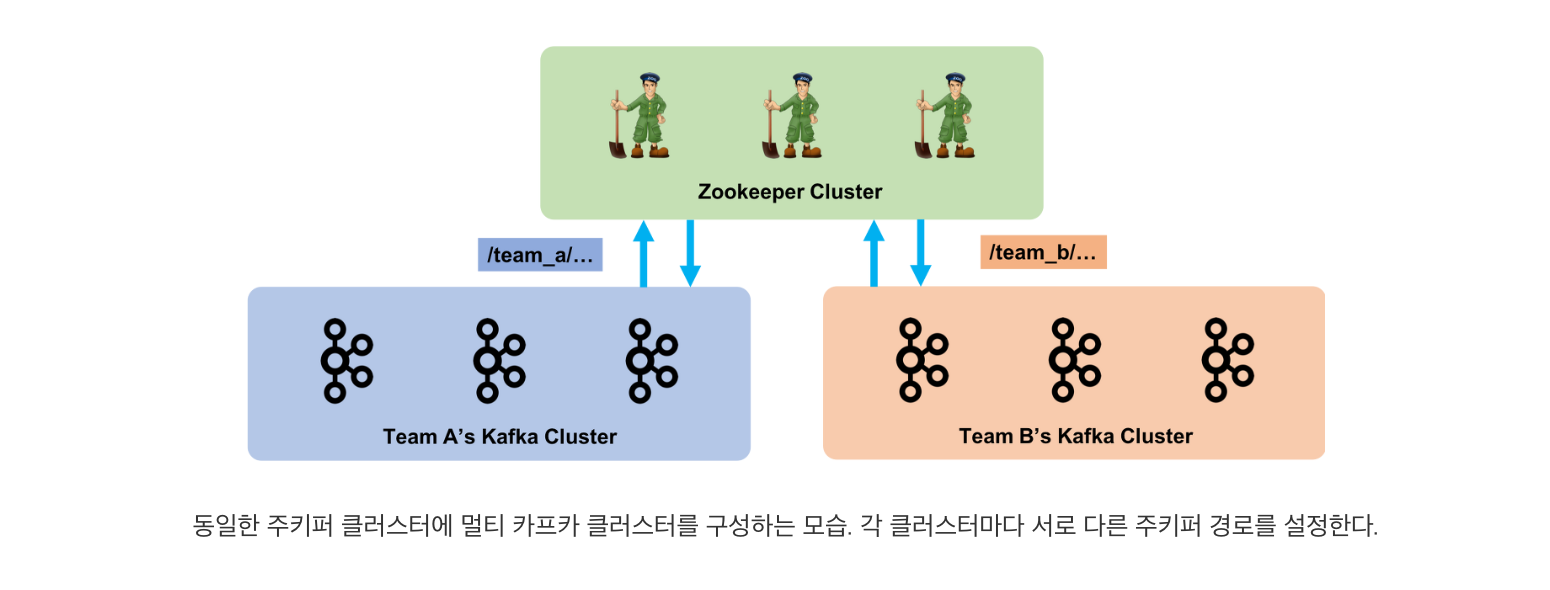
주키퍼는 디렉터리 형태로 데이터를 저장, 관리합니다. 그리고 카프카의 메타 정보는 클러스터 구성할 때, 주키퍼 연결 설정(zookeeper.connect)에서 지정된 디렉토리 하위에 저장됩니다. 따라서 동일한 카프카 클러스터는 주키퍼 연결 설정에서 동일한 디렉토리 경로를 가지며, 하나의 주키퍼 클러스터에 여러 카프카 클러스터가 동시에 구성될 수 있습니다.
Peer-to-Peer 구조
카프카 클러스터는 모든 브로커가 클라이언트의 요청을 처리할 수 있는 Peer-to-Peer(p2p) 구조를 가집니다. 이렇게 p2p 구조가 가능한 것은 클라이언트와 카프카 간 메타 데이터를 전달하는 과정이 있기 때문입니다(참고 : [Kafka 101] bootstrap.servers 설정에 관하여). 다만 염두해야 할 것은 브로커는 p2p 구조인 반면, 실제로 메시지를 전달받고 저장하는 단위인 파티션은 리더와 팔로워로 나뉘어 작업을 처리한다는 것입니다.
bootstrap.server 설정에 관하여
카프카 클라이언트(프로듀서와 컨슈머 등등)이 메세지를 발행, 구독하기위해 필수적으로bootstrap.servers를 설정한다.
이를통해 카프카 클러스터를 구성하는 전체 브로커에 대해 설정해주지 않아도 클라이언트는 각자의 브로커 자원 위치를 알고 작업을 수행한다.(메세지 보내거나 받을때 해당 토픽+파티션을 처리하는 브로커의 위치를 이미 모두 알고있음)
카프카 클러스터에서는 각 브로커들이 클러스터 전체 데이터의 일부분을 가지고있다(파티션!+replication>>여러 브로커에 산개되어있음)
개별 브로커는 클러스터 전체 데이터를 가지고있지 않기에, 클라이언트는 브로커와 연결하여 브로커 내부의 자원에 접근하기 위해, 클라이언트가 접근하고자 하는 자원의 위치를 알아야한다.
그래서 카프카는 클라이언트가 카프카와 처음 연결될떄, 자원들의 메타데이터를 공유하기위해 bootstrap.servers설정이 필요한것이다.(토픽, 파티션의 모든 메타데이터를 요청하기위한 주소)
bootstrap.servers 설정에는 몇 개의 브로커 호스트를 등록해야 할까? 너무 적게 입력하면 다른 브로커가 멀쩡히 구동 중임에도 불구하고 설정에 겨우 입력된 브로커가 중단된다면, 클라이언트는 카프카 클러스터와 연결할 수 없게 됩니다.
- 브로커 연결성공만 하면 클러스터에 등록된 모든 브로커와 토픽, 파티션의 메타데이터를 받음
- 클라이언트는 이제 해당하는 브로커 위치를 메타데이터에서 찾음
- 메타데이터는 클라이언트가 브로커에 처음 접근할때+주기적으로 갱신할때 요청한다.
현재 접근하고 있는 브로커가 비정상적인경우, 클라이언트가 접근하고 있던 리더 토픽 파티션의 위치가 변경된 경우 또한 갱신요청한다!
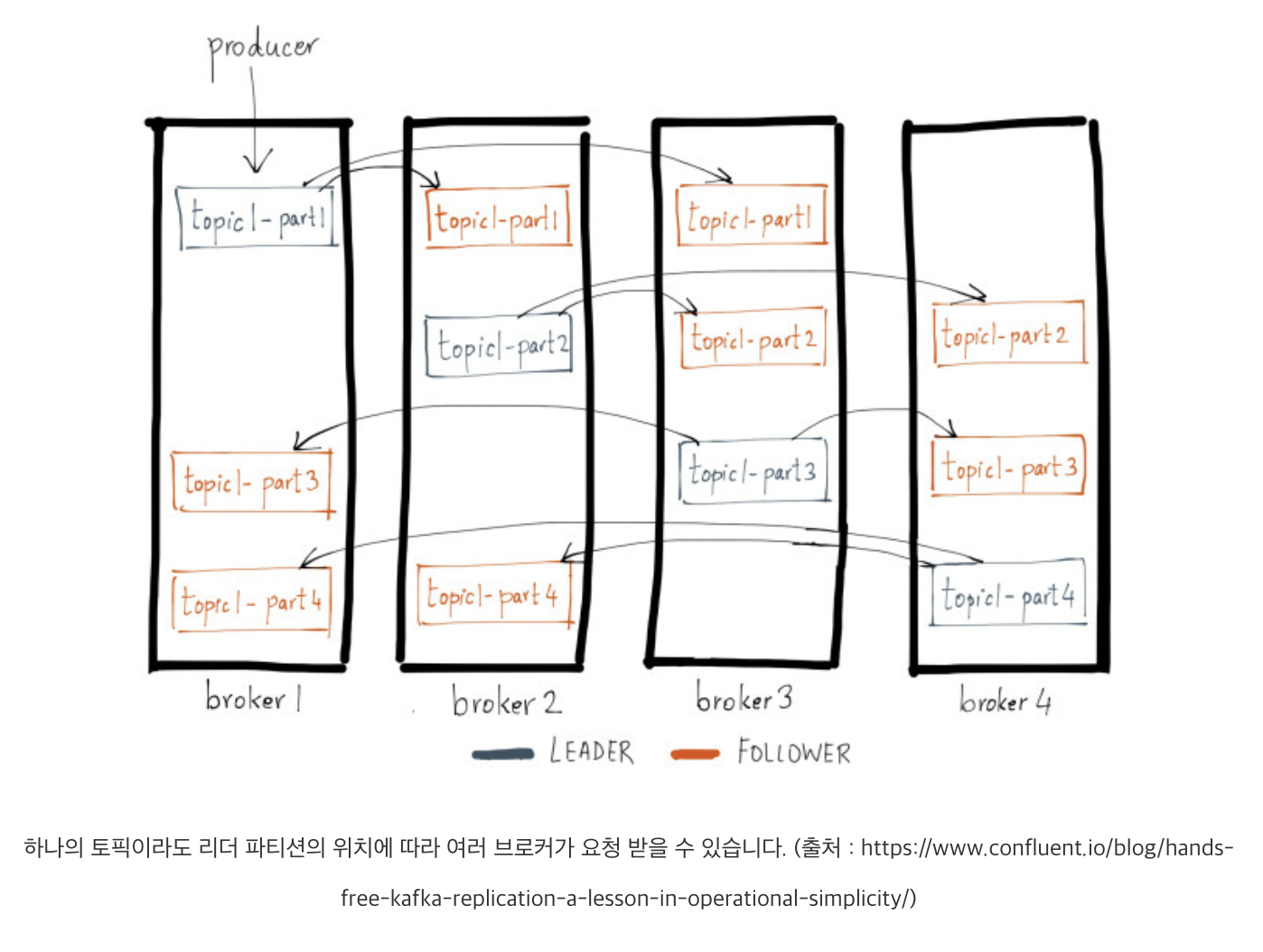
그림처럼 모든 메세지는 클러스터 안 브로커에 쪼개져있다. 그러므로 프로듀서가 토픽1-파티션1에 메세지를 전달하려면 해당 리더 파티션이 위치한 1번 브로커에 메세지를 전달해야한다.
3. 주요 브로커 설정
브로커는 여러 환경에 따라 다양한 설정을 할 수 있습니다. 이러한 설정의 대부분은 기본값이 제공됩니다. 따라서 별도로 설정해주지 않아도 되지만 다음 3가지 설정은 반드시 설정해줘야 합니다.
- broker.id
- log.dirs
- zookeeper.connect
broker.id 는 같은 카프카 클러스터에서 현재 브로커를 식별하기 위한 숫자입니다. 따라서 다른 브로커와 다른 숫자를 설정해야 합니다. 일반적으로는 0 혹은 1부터 순차적으로 설정합니다.
log.dirs 설정은 브로커가 프로듀서로부터 받는 메시지들을 저장할 위치 경로를 지정하는 설정입니다. 기본 값은 /tmp/kafka-logs입니다. 여기서 주의해야 할 것은 기본 값이 /tmp/ 하위에 지정되기 때문에 OS 설정에 따라 임의로 삭제될 수 있습니다. 그러므로 별도의 위치로 꼭 지정해주시길 바랍니다.
zookeeper.connect 는 카프카 클러스터의 메타 정보를 저장할 주키퍼에 관한 호스트 연결 정보를 가집니다. 호스트 연결 정보는 hostname:port로 구성되며, 동일한 주키퍼 클러스터의 여러 노드를 ‘, ‘로 구분한 문자열로 지정할 수 있습니다. 예를 들어 ‘zookeeper01:2181, zookeeper02:2181’와 같이 지정할 수 있습니다. 또한 앞서 언급한 것처럼 주키퍼 내부의 저장 위치를 함께 설정할 수 있습니다. 이럴 경우에는 ‘zookeeper01:2181, zookeeper02:2181/my/path’와 같이 설정하면 됩니다.
이 외에도 여러 설정이 존재하는 데, 개인적으로 중요하다고 생각되는 설정을 몇 가지 더 소개하겠습니다.
- advertised.listeners : 클라이언트가 브로커를 바라볼 때의 브로커 호스트 정보.
- auto.create.topics.enable : 클라이언트가 특정 토픽으로 요청했을 경우 자동 생성 여부. (기본값 true)
- offsets.topic.replication.factor : 오프셋 토픽의 복제 계수. (기본값 3)
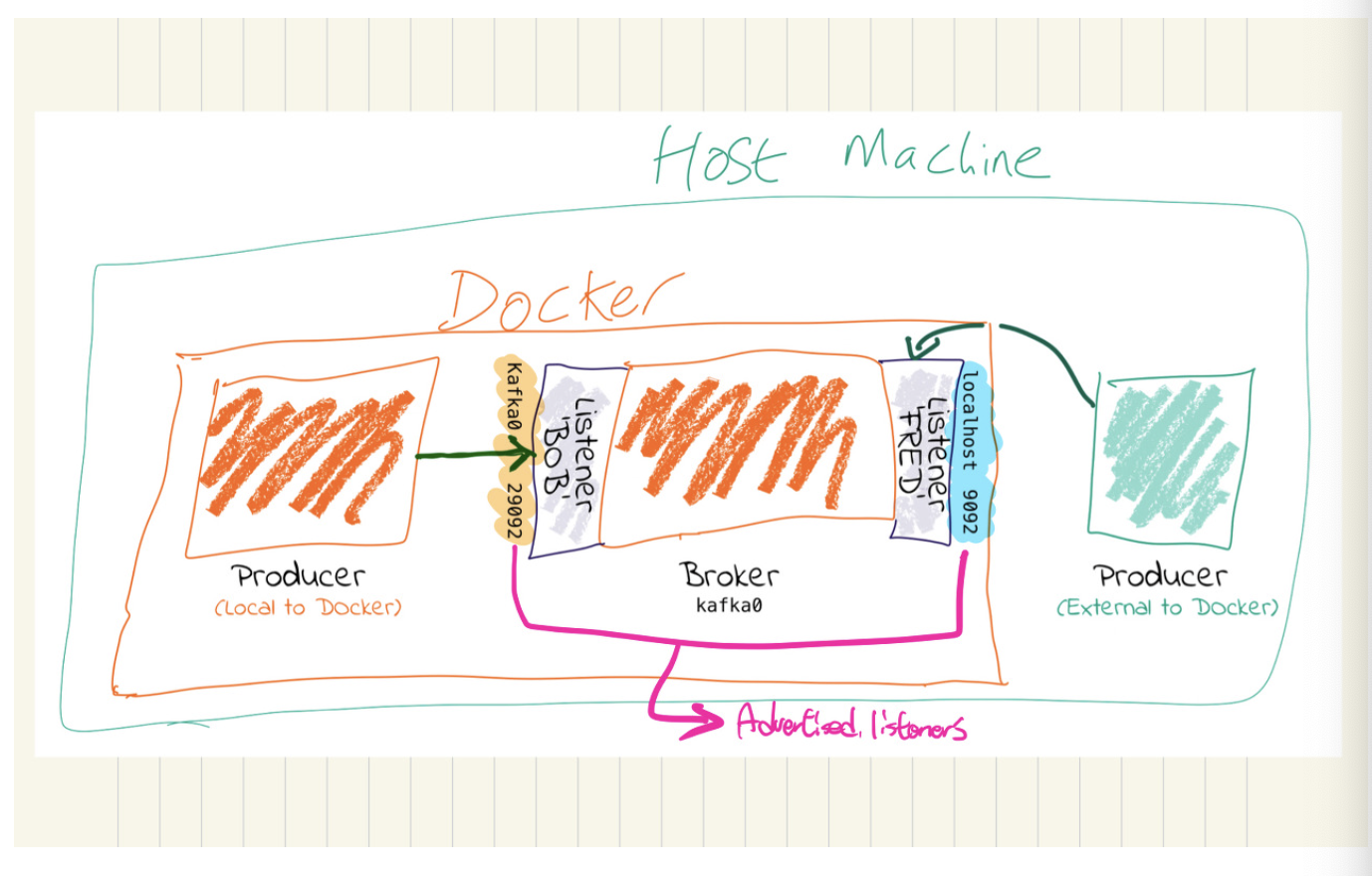
브로커는 하나 이상의 리스너(listener)를 통해 외부 요청을 받습니다. advertised.listeners 는 클라이언트가 브로커에게 요청할 때, 클라이언트 입장에서 브로커를 찾을 수 있는 호스트 정보를 설정합니다. 이 설정은 초기 메타 데이터 전달 과정에서 클라이언트로 전달되고, 이 정보를 바탕으로 클라이언트가 브로커로 요청합니다. 여기서 중요한 것은 클라이언트와 브로커의 네트워크 환경이 다를 경우, 클라이언트가 브로커를 찾을 수 있도록 설정해줘야 한다는 것입니다. (제가 이 설정 때문에 많이 헤맸습니다.)
auto.create.topics.enable 는 운영 과정에서 중요한 설정입니다. 실제 상용 환경에서 브로커는 무수히 많은 클라이언트와 맞이하게 됩니다. 그렇게 때문에 적절한 토픽의 관리가 필요한데, 만약 이 설정을 true로 설정하면 클라이언트의 요청에 따라 토픽이 지속적으로 생성됩니다. 이는 운영 상에 큰 골칫거리가 될 수 있겠습니다.
offset.topic.replication.factor 는 개발 환경 구성에서 많이 부각되는 설정입니다. 오프셋(offset) 토픽의 복제 계수에 관한 설정인데, 만약 브로커를 1대로 구성하게 되면 기본값이 3과 충돌하여 브로커가 실행되지 않습니다. 복제 파티션들은 같은 브로커에 존재할 수 없기 때문입니다. 그러므로 개발 환경에서 1대로 구성할 경우에는 꼭 해당 설정을 1로 설정해야 합니다.
이외에도 보안, 로그 관리, 압축 등에 관한 다양하고 중요한 설정들이 있습니다. 자세한 내용은 공식 문서를 참고하시길 바랍니다.
4. 브로커 내부 동작 요소
카프카 브로커는 프로듀서로부터 메시지를 발행받아 이를 저장하고, 컨슈머로 전달합니다. 이 과정을 위해 브로커 내부에는 다양한 동작 요소들이 존재합니다. 아래는 그 중 3가지를 간단히 정리했습니다.
컨트롤러
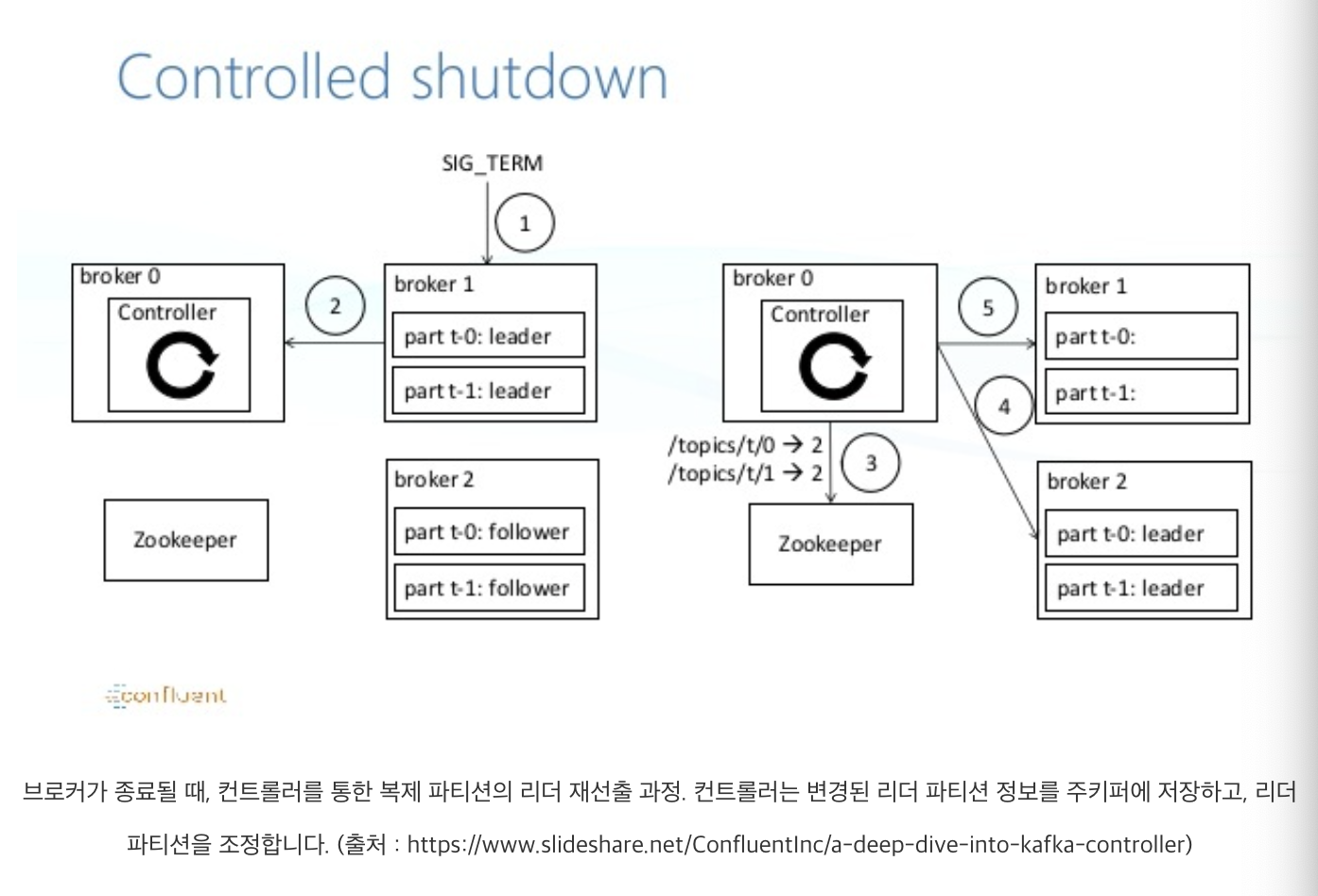
컨트롤러(Controller)는 하나의 클러스터에서 하나의 브로커에 부여되는 역할로, 마치 지휘자와 같은 역할입니다. 컨트롤러는 브로커들의 생존 여부(liveness)를 체크합니다. 그리고 만약 임의의 브로커가 중단되었을 경우, 해당 브로커에 있었던 리더 파티션을 탈락시키고 다른 팔로워 파티션들 중 하나를 리더로 뽑습니다(leader election). 이 과정은 카프카의 실패 극복(failover) 전략 중 중요한 부분을 담당하기 때문에 컨트롤러의 역할은 중요합니다. 참고로 컨트롤러가 중단되는 경우에는 주키퍼가 이를 감지하여 새로운 컨트롤러를 선출합니다.
메시지 저장과 메시지 파일 관리
브로커는 프로듀서로부터 전달되는 메시지를 로그(log) 자료구조 형태로 디스크에 저장합니다. 로그 자료구조는 새로운 쓰기 작업이 중간에 삽입되지 않고 오로지 끝에서만 되는 append-only 특징을 가집니다. 일반적으로 우리가 이야기하는 시스템 로그, 애플리케이션 로그들도 이러한 특징을 가집니다. 로그의 append-only 특징에 관한 자세한 설명은 별도의 글로 정리하도록 하겠습니다. 다만, 가장 중요한 것은 쓰기 작업이 끝에서만 이뤄지므로 브로커에 이미 쓰여진 메시지(로그)는 변경이 불가합니다. 하지만 그렇기 때문에 빠른 쓰기 작업이 가능합니다.
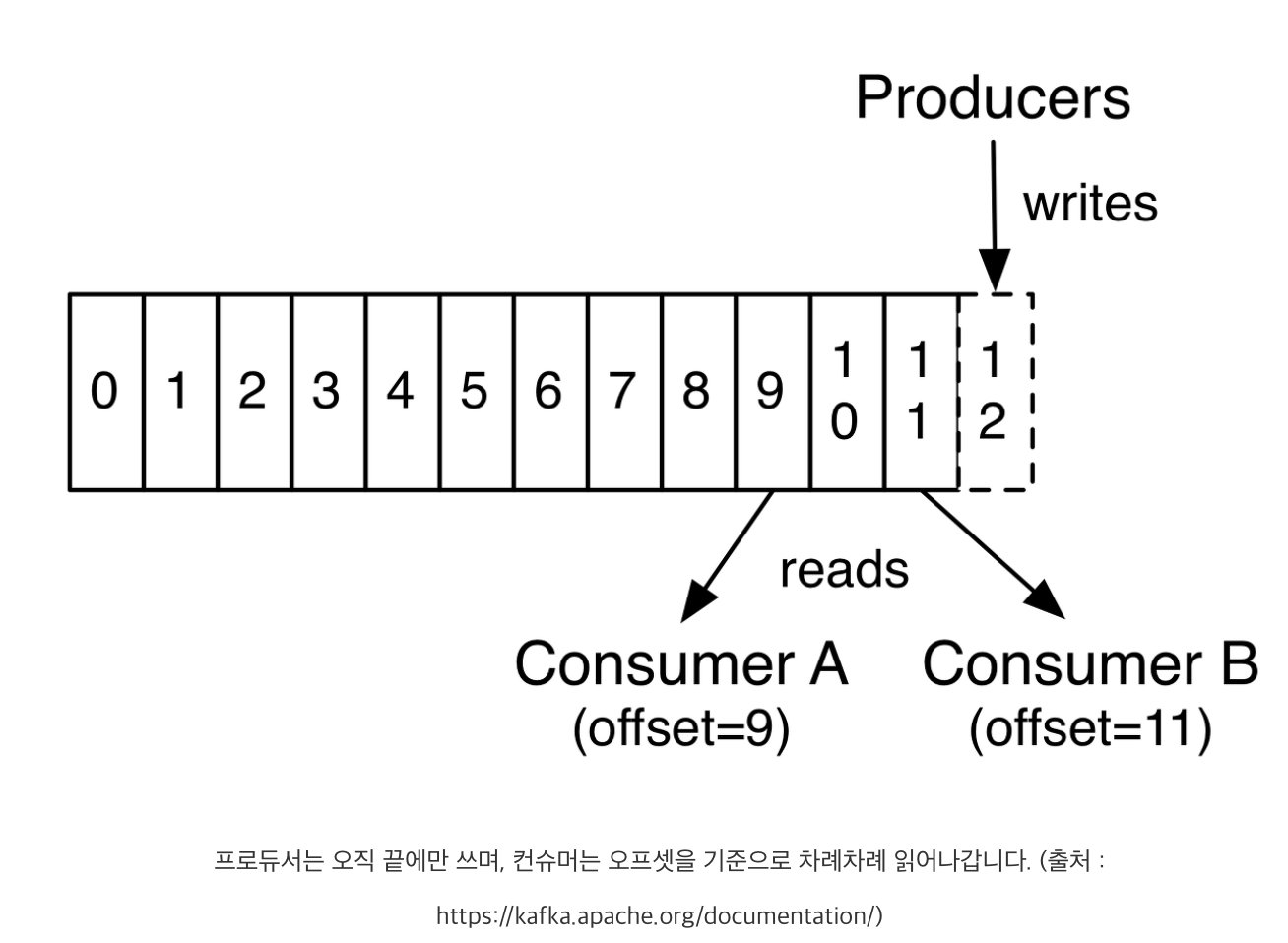
메시지가 브로커에 저장될 때는 메시지 내용과 함께 오프셋 정보가 저장됩니다. 메시지의 오프셋은 메시지를 구분하는 식별자 역할을 하며, 메시지의 삽입에 따라 0부터 꾸준히 증가합니다.
브로커에 저장되는 메시지들은 파티션 별로 세그먼트(segment)라는 파일로 저장됩니다. 예를 들어 토픽 A에 3개의 파티션이 있다면, 각 파티션이 위치한 브로커의 log.dirs 하위에는 해당 파티션의 세그먼트 파일이 존재합니다. 그리고 프로듀서가 파티션으로 발행되는 메시지를 세그먼트 파일에 쓰고, 컨슈머는 이 파일을 읽어감으로써 메시지를 구독합니다.
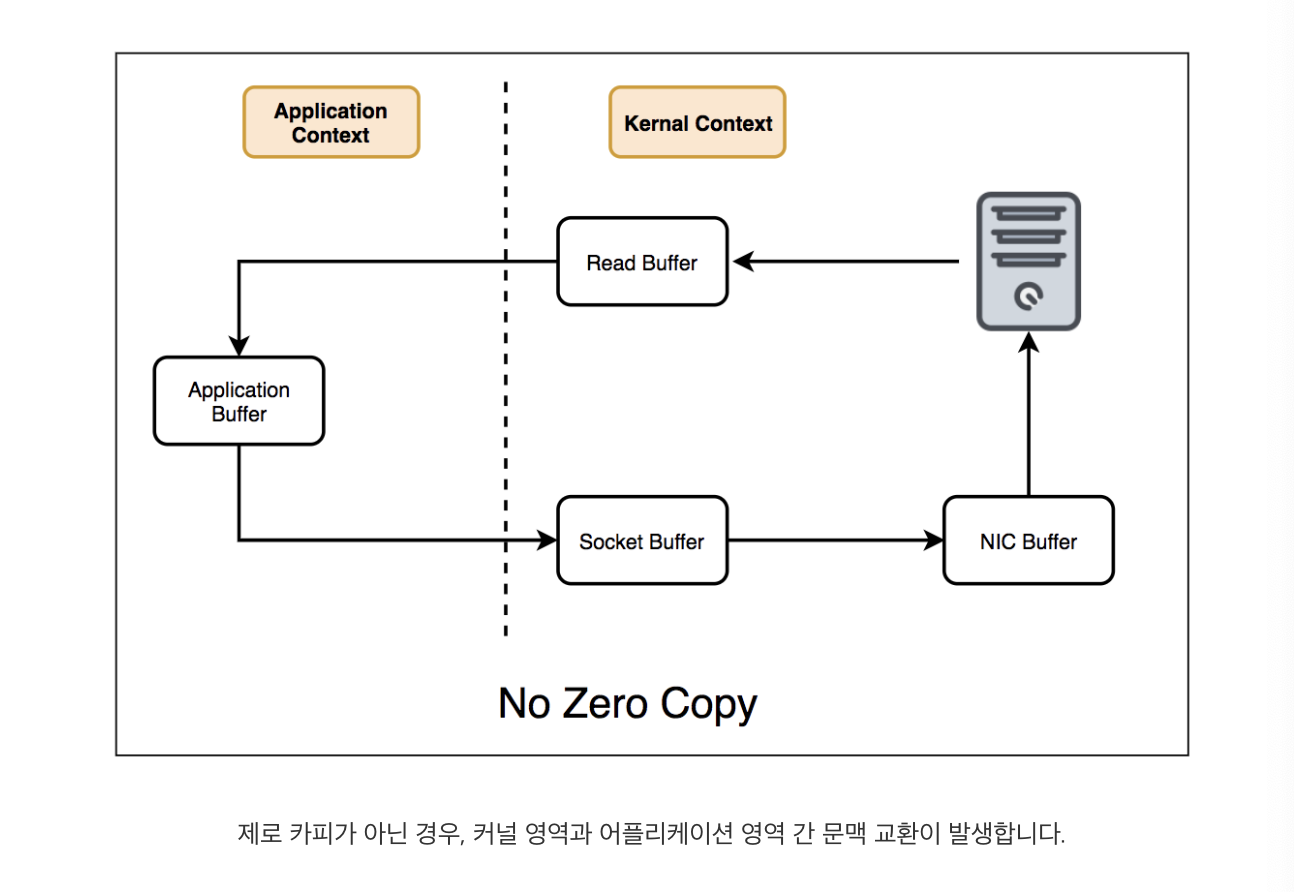
Zero-copy
카프카는 다른 메시징 큐보다 뛰어난 성능을 제공합니다. 그럴 수 있는 이유 중 하나가 제로 카피(Zero-copy) 기술을 사용하기 때문입니다. 제로 카피 기술은 브로커가 세그먼트 파일로부터 메시지를 읽고, 이를 네트워크로 전달하는 과정에서 문맥 교환(context switch)이 없도록 하는 기술입니다.
- zero-copy아닌 경우, 애플리케이션 영역 간 문맥 교환 발생
- zero-copy인 경우, 애플리케이션 영역 간 문맥 교환없이 커널 영역 안에서만 작업이뤄짐
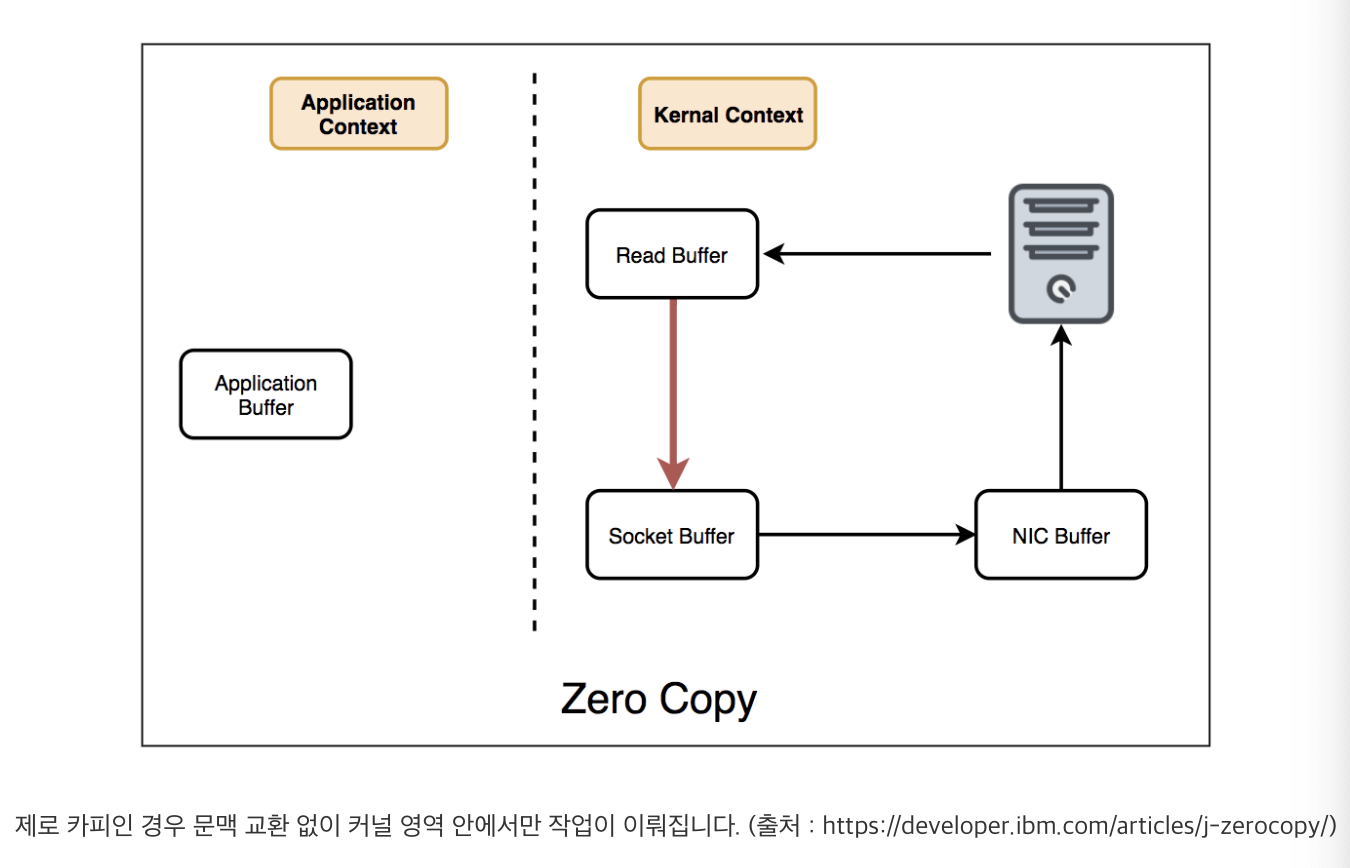
이처럼 카프카는 제로 카피를 통해 더욱 높은 성능을 제공합니다. 다만, 메시지 암호화(SSL)를 설정한 경우에는 메시지 암, 복호화를 위해 어쩔 수 없이 문맥 교환이 발생하므로 제로 카피 기술을 사용할 수 없게 됩니다
컨슈머
1. 카프카 컨슈머
1컨슈머는 컨슈머 API와 그것으로 구성된 애플리케이션을 말합니다. 일반적으로 컨슈머가 토픽을 구독(Subscribe) 혹은 읽는다(Read)고 하는데, 이는 컨슈머가 토픽 파티션에 저장된 메시지들을 가져오는 것을 말합니다.
카프카 컨슈머의 다음 3가지 특징을 통해 더욱 효율적이고 유연한 메시지 구독 기능을 제공합니다.
- Polling 구조
- 단일 토픽의 멀티 컨슈밍
- 컨슈머 그룹
Polling 구조
일반적으로 다른 메시징 큐는 메시지 큐에서 메시지를 Push 합니다. 카프카 구성 요소로 예를 들면 브로커가 컨슈머로 메시지를 보내는 방식입니다. 하지만 이런 Push 방식의 가장 큰 단점은 메시지 큐가 컨슈머 측의 처리 성능을 염두해야 합니다. 즉, 메시지 큐가 컨슈머로 메시지를 Push 할 때, “컨슈머가 이 정도는 처리할 수 있겠지!” 하고 컨슈머 환경을 고려해야 합니다.
이와 반대로 카프카는 컨슈머가 브로커로부터 메시지를 요청하는 Polling 구조로 설계되었습니다. 즉,컨슈머는 자신이 원하는 만큼의 브로커로 메시지를 요청합니다. 이러한 구조의 가장 큰 장점은 각 컨슈머가 자신의 환경에 메시지 구독 성능을 최적화할 수 있다는 것입니다. 추가로 브로커는 컨슈머가 요청하는 것만큼 메시지를 전달해주면 되기 때문에 더 이상 컨슈머의 환경을 고려할 필요가 없습니다.
객체지향 SOLID 원칙 중 단일 책임 원칙 맥락과 유사하죠?
단일 토픽의 멀티 컨슈밍
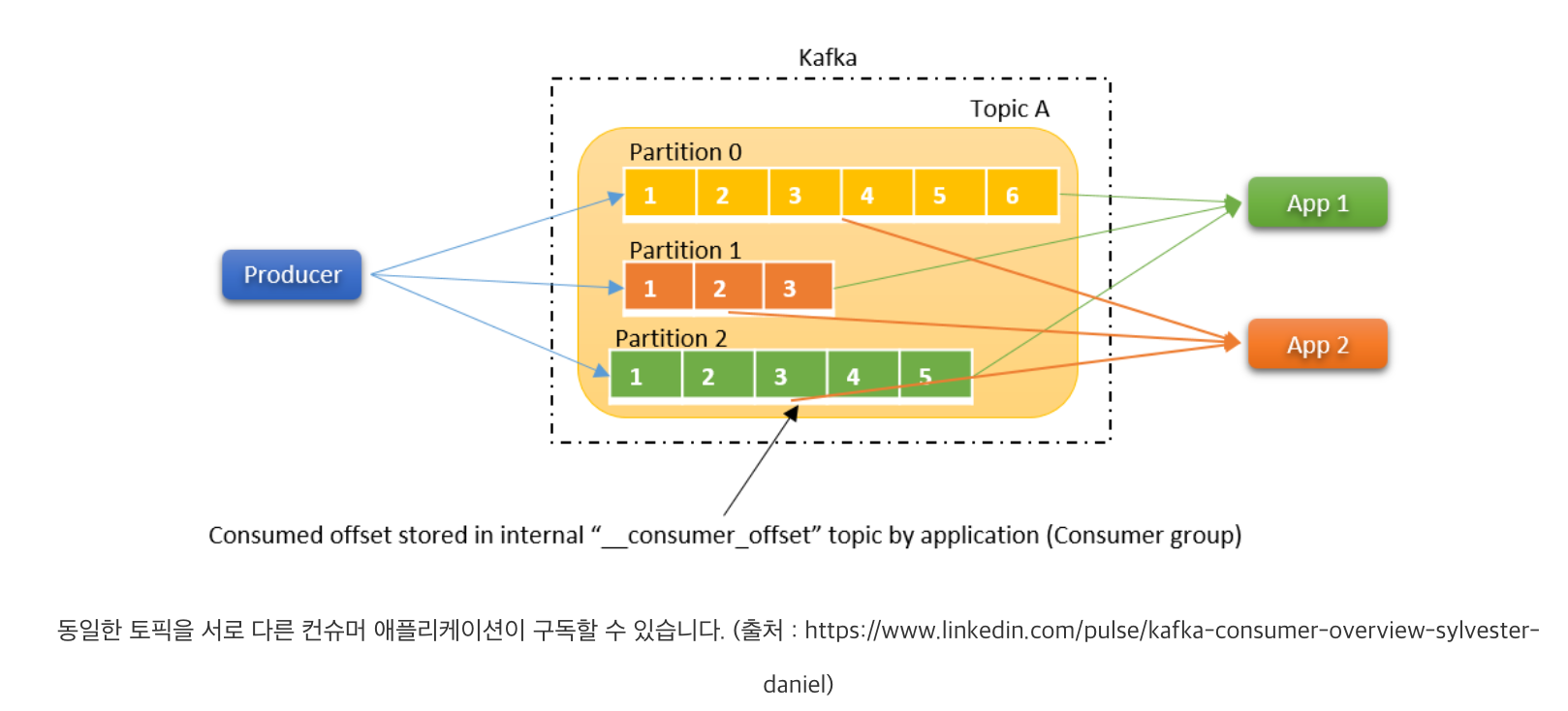
카프카 컨슈밍의 또 다른 특징 중 하나는 하나의 토픽에 서로 다른 컨슈머 애플리케이션이 동시에 구독할 수 있다는 것입니다. 위 그림에서처럼 하나의 토픽(Topic A)을 컨슈머 App 1과 App 2이 동시에 구독할 수 있습니다. 이렇게 단일 토픽에 대한 멀티 컨슈밍이 가능한 이유는 컨슈머가 메시지를 읽을 때 브로커의 메시지가 삭제되는 것이 아니기 때문입니다. 대신에 각 컨슈머가 어느 토픽 파티션의 어느 오프셋까지 읽어갔는 지를 컨슈머 오프셋(__consumer_offset)이라는 토픽에 저장합니다.
컨슈머 오프셋으로 얻어지는 장점은 멀티 컨슈밍만이 아닙니다. 컨슈머 애플리케이션이 메시지 구독 중 중단되었다가 다시 구동되는 경우, 컨슈머 오프셋에 저장된 정보를 통해 자신이 어디서부터 메시지를 읽어야하는 지 알 수 있습니다. 즉, 컨슈머 상태와 관계 없이 안정적인 메시지 구독이 가능해집니다.
컨슈머 그룹
브로커는 성능을 위해 하나의 토픽을 여러 파티션으로 병렬 구성하여 처리합니다. 하지만 둘 이상의 파티션을 하나의 컨슈머로만 처리한다면 성능 상의 문제가 발생할 수 있습니다. 그래서 카프카 컨슈머는 하나 이상의 컨슈머가 컨슈머 그룹(Consumer Group)을 구성하여 하나의 토픽을 구독할 수 있습니다.
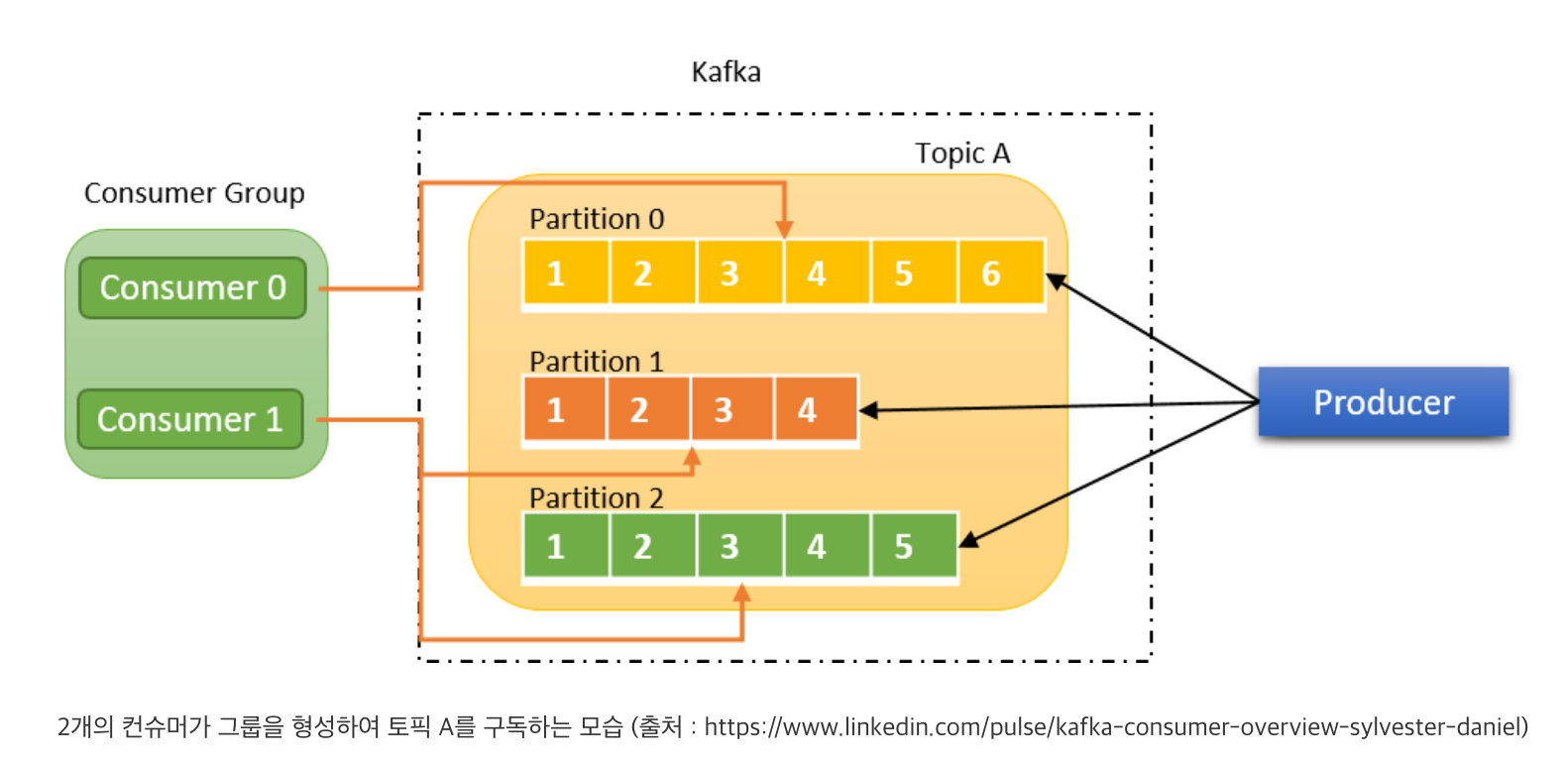
컨슈머 그룹 내의 컨슈머는 토픽 파티션의 소유권(혹은 구독권)을 나눠 갖습니다. 예를 들면, 위 그림은 파티션 3개로 이루어진 토픽 A를 2개의 컨슈머가 컨슈머 그룹을 구성하여 구독하는 모습입니다. 컨슈머 0은 파티션 0의 소유권을 가지고 구독합니다. 마찬가지로 컨슈머 1은 파티션 1과 2의 소유권을 가지고 구독합니다. 이처럼 같은 컨슈머 그룹의 컨슈머들은 소유권을 가진 파티션만 구독합니다.
그렇다면 컨슈머 그룹에 컨슈머가 추가되거나, 이탈하게 되면 어떻게 될까요? 이럴 때는 컨슈머 그룹 내부에서 파티션의 소유권이 재조정됩니다. 이러한 파티션 소유권 재조정을 리밸런싱(Rebalancing)이라고 합니다. 리밸런싱은 컨슈머 그룹 내에 특정 컨슈머의 상태가 변경되더라도 다른 컨슈머들이 유연하고 안정적으로 토픽을 구독할 수 있도록 도와주는 기능입니다. 리밸런싱 과정은 다소 깊이가 있는 내용이기 때문에 별도의 글에서 다루도록 하겠습니다.
구현
카프카 다운로드
- 포스트에서는 2.8버전 다운로드
https://kafka.apache.org/downloads
Scala 2.12 - kafka_2.12-2.8.1.tgz
1 | $ tar xvf kafka_2.13-2.8.1.tgz //압축해제 |
Zookeeper 실행 및 kafka실행
1 | bin/zookeeper-server-start.sh config/zookeeper.properties //zookeeper 실행 |
Kafka 토픽 생성
1 | bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092 // quickstart-events라는 토픽을 localhost:9092에 생성 |
producer 실행 메세지 발행
1 | bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092 |
Consumer 실행 메세지 발생
1 | bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092 |
producer에서 메세지 입력했던것 출력되는지 확인
Java 프로젝트 생성 및 dependency추가
- 참고로 새로 SpringBoot시에는 kafka, SpringWeb, java 11, gardle 확인하기
dependencies에 추가
1 | implementation 'org.apache.kafka:kafka-clients:3.0.0' |
Consumer 작성
1 | public class Consumer { |
Producer
1 | public class Producer { |
예시처럼 보내면 결국 ProducerRecord의 해당 인스턴스는 topic, value만 값을 갖고 나머지는 null처리로 생성되어 보내진다.
1
2
3public ProducerRecord(String topic, V value) {
this(topic, null, null, null, value, null);
}
오류 해결
group consumer로 10000건 처리 테스트 시 리더 컨슈머만 처리하는 현상
- group.id가 같은 컨슈머 2개 이상을 지켜본결과, 리더 컨슈머는 계속해서 Sending FETCH request with header RequestHeader를 시도하는데,나머지들은 계속 Sending Heartbeat request 및 heatbeat만 되었고 심지어 해당 토픽으로 브로커에 10000건을 올려놔도 리더 제외하곤, 처리하지 못했다.
해결
- 해당 토픽에 파티션이 0이였으므로, 같은 그룹에있는 컨슈머라도, 파티션이 0이였으므로 리더만 해당 파티션에 배치되었고, 나머지들은 처리하는 파티션이 존재하지않아서, heartbeat만 리더에게 보내는것이였음.
- 즉, 파티션 ≥ 컨슈머 이다. 파티션당 하나의 컨슈머가 가장 높은 처리 성능을 보이고,그 이상의 컨슈머들은 일처리 못한다.
kafka config 정리 (P-C순)
Producer config 정리
다음 클래스의 주석에 다음과 같은 설명이 있다.
- RecordAccumulator
- 큐 역할을 하는 클래스
- 한계가 있는 메모리 양을 사용하며 메모리를 다 사용했을 때 블록한다.
- Sender
- 카프카 브로커에 레코드를 보내는 백그라운드 스레드
아래 그림을 참조하면, 설정값이 어디에 표시되어 있는지 참고하여 의미를 살펴보자
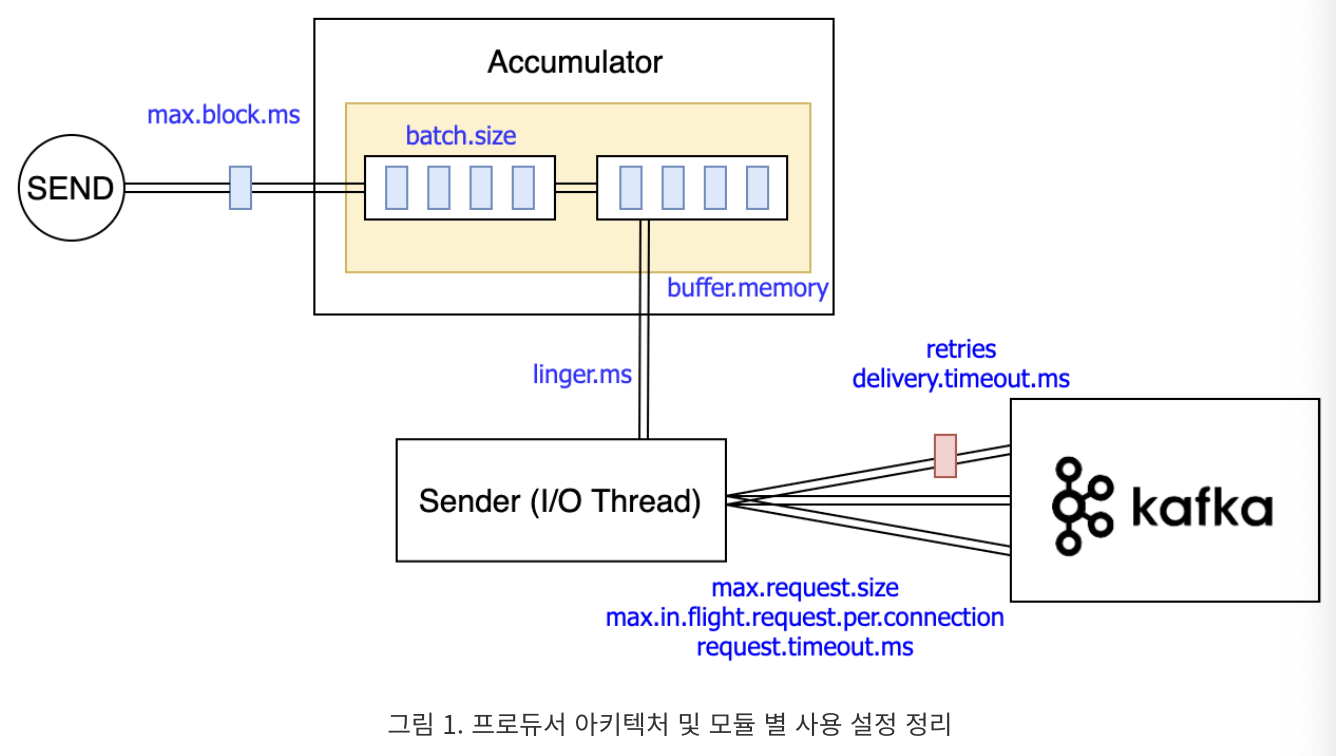
Accumulator
Accumulator는 레코드를 축적하는 역할이다.
그래서 레코드를 축적할 때 사용하는 버퍼의 크기 (buffer.memory), 레코드를 묶는 양 (batch.size), 버퍼가 찾을 때 블록할 시간 (max.block.ms) 설정이 있다.
buffer.memory
- 프로듀서가 브로커에 보낼 레코드를 모아두는 버퍼의 전체 메모리 바이트 수 이다. 프로듀서가 사용하는 전체 메모리 크기는 buffer.memory와 대략 비슷하다. 정확히 일치하지 않는 것은 압축하는 과정과 브로커에 보내는 과정에서 사용하는 메모리가 추가로 들기 때문이다.
max.block.ms
- 버퍼가 가득 찾을 때 send(), partitionsFor() 메서드를 블록하는 시간이다.
batch.size
- 프로듀서는 레코드를 한번에 하나씩 발송하지 않고 묶어서 발송한다. 묶어서 발송해야 네트웍 단계가 줄어드며 성능 향상이 도움이 된다.
- batch.size는 레코드를 묶는 byte 단위의 사이즈이다. 이 크기보다 크게 레코드를 묶지 않는다.
- 그렇다고 배치가 가득찰 때까지 프로듀서가 기다린다는 것은 아니다.
Sender
Sender는 레코드를 브로커에 전달하는 역할이다. Accumulator가 쌓아놓은 레코드를 비동기로 브로커에 계속 발송한다.
Accumulator↔ Sender
linger.ms
- 사전으로 정의를 찾아봤더니 ‘꾸물거리다’가 눈의 들어왔다.
- 브로커로 발송하기 전에 Accumulator에 축적된 데이터를 꾸물거리며 가져오는 것이다. 이유는 부하 상황에 브로커에 요청 수를 줄이기 위함이다. 다음 메세지를 바로 보내지 않고 딜레이 시간을 주는 것이다.
- 한 파티션에 batch.size 만큼 레코드가 있으면 linger.ms 값을 무시하고 발송한다.(꽉참)
- 기본값은 0으로 대기하지 않는다.
Sender↔ Broker
retries
- 레코드 발송에 실패할 경우 재시도 하는 회수이다. 기본값이 2147483647 이다.
- 여기서 의문은 이렇게 큰 재시도 횟수를 한 메세지에 대해서 계속 발송하면 실패할 경우 다른 메세지는 전송 시도도 못하고 버퍼에 데이터가 쌓이는지 여부이다. retries를 다 채우지 않고도 재시도를 멈추는 다른 설정이 있다. delivery.timeout.ms 이다.
- 일반적으로 재발송 관련해서 retries 보다 delivery.timeout.ms로 제어한다.
delivery.timeout.ms
- send() 메서드를 호출하고 성공과 실패를 결정하는 상한시간이다. 브로커로부터 ack을 받기 위해 대기하는 시간이며 실패 시 재전송에 허용된 시간이다. 복구할 수 없는 오류가 발생하거나 재시도 횟수를 다 소모하면 delivery.timeout.ms 설정 시간 보다 먼저 에러를 낼 수 있다.
- request.timeout.ms과 linger.ms의 합보다 같거나 커야 한다.
max.request.size
- 요청할 수 있는 최대 bytes 사이즈.
- 거대한 요청을 피하기 위해 프로듀서에 의한 한 배치에 보내는 사이즈를 제한한다. 압축되지 않은 배치의 최대 사이즈.
- 서버에서는 별도의 배치 사이즈 설정을 가지고 있다.
max.in.flight.request.per.connection
- 블록되기 전에 클라이언트가 보내고 받지 못한 요청의 최대 개수. 한번에 브로커와 통신하는 개수로 이해했다.
- 만약 1보다 높은 값을 설정하면 재발송 과정에서 순서가 변경되는 위험이 발생한다.
request.timeout.ms
- 요청 응답에 대한 클라이언트의 최대 대기 시간. 타임아웃 시간 동안 응답을 받지 못하면 요청을 다시 보낸다.
- 불필요한 재시도를 줄이려면 브로커 설정 replica.lag.time.max.ms 보다 큰 값이어야 한다.
replica.lag.time.max.ms
- 브로커 팔로워가 복제를 위한 패치 요청을 하지 않을 경우 ISR에서 제외하는 시간이다.