
7주차 발표 요약
- ioc
- di
- pattern
- component
6주차 복습 및 핵심
redis
- 락획득 -> 트랜잭션 시작-> 비즈니스 로직 -> 트랜잭션 종료 -> 락 해제 로 반드시해야헸다
반드시 참조 https://helloworld.kurly.com/blog/distributed-redisson-lock/
트랜잭션이 전파가 잘되는지 매우매우 중요.
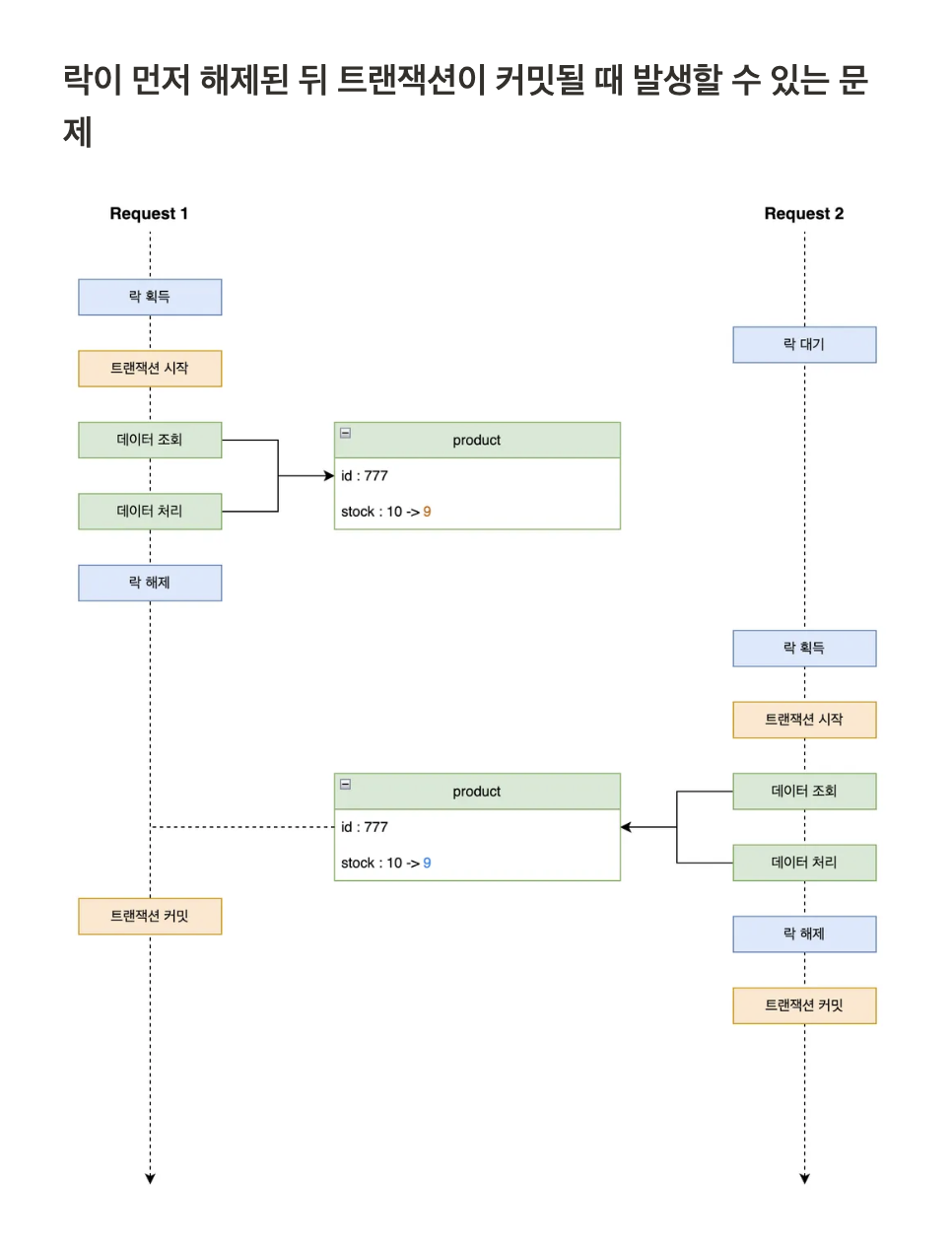
- aop만 설정해서 락 획득을 하게되면, 락이 먼저 해제된 뒤 트랜잭션 커밋 직전에 데이터 조회하면 정합성 달라짐.
포인트에서 getLock을 하더라도, userId마다 다른 key를 두고 lock을 거는것이맞음 -> userId + 상위의 액션 이름
- key = #userId + #point
application이 redis 로. cache 사용시 훨씬 빠른이유
- 실무에서는 DB는 철저히 분리된 서버를 쓰고, 망을 뚫어서 보통사용, application + redis는 가까운 내부망 -> redis가 빠름
- redis는 RAM에 값이 있기때문에 처리 응답 또한 빠름
TestCode의 병렬 부하 만으로 부하발생 환경에서 동시성 테스트가 가능한가?
- Jmeter, nGrinder를 사용하여 부하테스트
7주차 발제
⛵ 이번 챕터 목표
- Redis 의 특성에 따른 활용 방식을 고민해보고 올바른 설계로 풀어낼 방법을 고민해봅니다.
- 다량의 트래픽을 처리하기 위해 적은 DB 부하로 올바르게 기능을 제공할 방법을 고민해 봅니다.
Redis 자료구조
- Sorted Sets -> key, value, score까지 갖을수있는 자료구조
- 순위, 랭킹, 정렬에 매우 유용하다
- repository에서 redis를 읽어온다면, [key,value,key,value …] 배열이 올텐데 이것을 domainEntity로 변경하는것은 static에서 정의해서 domainEntity로 변환후 service에서는 domainEntity만 가지고 처리하는것이좋다
- ttl설정이 반드시 필요. 보통 하루, 일주일 등등하는것이 좋다
실전 활용 예시
인기 상품 조회 랭킹 (24시간 클릭 수 기준)
ZINCRBY product:ranking:clicks:20240429 1 product123- 매일 자정 배치로 새로운 키 생성 및 TTL 부여
사용자 게임 랭킹
ZADD game:ranking:user 5000 userA- 클라이언트에게
ZREVRANK결과 전달하여 등수 노출
시각화 전략
- Redis에서 Top N을 가져와 DB 캐싱 → 사용자에게 제공
- 그래프 구성: 시간대별 랭킹 변동, 내 순위 추이 등 추가 분석 가능
Redis를 write-through로 사용가능
- 선착순 쿠폰 발급 재고량을 Redis에만 저장하고 활용함
7주차 발제 추가 질문
첫번째 질문 및 답변
쿠폰, 인기상품쪽 DB로직또한 기존 service는 제거하나요?
- 기존의 service는 놧두고, 새로운 service를 만들고 -> 쿠폰, 인기상품쪽 DB로직또한 기존 service에 놧두기
redis가 죽으면 DB를 바라봐야하는거아닌가요?
- 절대아님. application은 redis만을 바라보는것은 그것만 바라보게하고, redis가 완전 죽으면, failover 실행하고 응답하거나, 다른페이지를 보거나 장애 페이지 보여주는것이맞다. DB를 읽어서 처리하지마라
코치님, 분산락 aop를 구현할때 트랜잭션이 걸려있어도 비지니스 로직이 종료된 후 트랜잭션이 커밋되고 그 후에 finally이 실행되서 unlock이 되는 순서로 예상을 했는데 finally이 먼저 된 후에 트랜잭션이 커밋된다는 말이 이해가 잘 가지않습니다. 다시 한번만 설명해주실 수 있나요 ?
@분산락 AOP을 구현할때, 아래와 같이 트랜잭션을 반드시 포함하는게 좋다.
그래야 항상 트랜잭션이 먼저끝나는것을 보장할수있다.
aop로 동작하고 안에서 완전히 순서를 보장하기 위한 방법/** * @DistributedLock 선언 시 수행되는 Aop class */ public class DistributedLockAop { private static final String REDISSON_LOCK_PREFIX = "LOCK:"; private final RedissonClient redissonClient; private final AopForTransaction aopForTransaction; public Object lock(final ProceedingJoinPoint joinPoint) throws Throwable { MethodSignature signature = (MethodSignature) joinPoint.getSignature(); Method method = signature.getMethod(); DistributedLock distributedLock = method.getAnnotation(DistributedLock.class); String key = REDISSON_LOCK_PREFIX + CustomSpringELParser.getDynamicValue(signature.getParameterNames(), joinPoint.getArgs(), distributedLock.key()); RLock rLock = redissonClient.getLock(key); // (1) try { boolean available = rLock.tryLock(distributedLock.waitTime(), distributedLock.leaseTime(), distributedLock.timeUnit()); // (2) if (!available) { return false; } return aopForTransaction.proceed(joinPoint); // (3) } catch (InterruptedException e) { throw new InterruptedException(); } finally { try { rLock.unlock(); // (4) } catch (IllegalMonitorStateException e) { log.info("Redisson Lock Already UnLock {} {}", kv("serviceName", method.getName()), kv("key", key) ); } } } } <!--0-->
redis 는 메모리 기반이라 down 시 메모리가 다 날라가게 될텐데, 이에 대한 백업플랜은 카카오의 설계와 같이 여러대의 redis 를 클러스터 구성으로 보장시키는걸까요?
- 이에 대한 대응은 쿠버가 pod을 종료할때, 한번에 다 날아가는것이아닌, 컨테이너가 종료가 될때, sh가 실행되면서 백업본이 생기도록, 등등 전체 기록하는것들이 많기때문에, 그게 생각안해도된다
- Redis에만 저장을 하게되면 TTL이나 자체 메모리 정리(Eviction)로 인해 데이터가 소실될 위험이 있지 않나요?
- 쿠폰 발급에 대해서만 Redis으로 하면되고, noSql처럼 쓰기도하므로, handler, logging 등 정책으로 푼다. ->
- 1번의 이유로 만약 DB에도 중복저장을 해야한다면, Write-Behind , Read-Through전략이면 괜찮을까요?
- 쿠폰 발급에 대해서만 Redis으로 하면되고, noSql처럼 쓰기도하므로, handler, logging 등 정책으로 푼다. ->
- 비동기 과제 쿠폰 선착순 발급에서 동시성 문제를 고민하고 있는데, 레디스에도 트랜잭션이나 db락 같은 개념이 있을까요? 잠깐 찾아봤을 때는 watch, multi, exec을 이용하거나 lua 스크립트를 써야될것 같은데 권장되는 방식이 있을지 궁금합니다.
- db처럼 redis를 쓴다고하면 쿠폰 발급처리시 til 이나 만료 방식을 지정해주지않고 수동으로 관리하나요?
- 아 네 정책을 잘정해야합니다. BE에서 redis로 쿠폰 재고량 차감 요청 및 발급된 유저+ coupon 정보를 바로 저장하고 해당부분을 추후에 RDB에 저장함.
- 쿠폰발급은 비동기로 한다면 어떻게?
- 폴링, 푸시 두가지에서 고민해서 해결함
질문 및 답변
멘토링
트랜디한것 키워드 공부 필요
Spring, RDBMS, Redis, Kafka => 20년차까지 설계 가능
Redis = 조회 성능을 압도적으로 높일 수 있는 수단
Kafka = 쓰기 성능을 압도적으로 높일 수 있는 수단
10분에 100개씩 활성화시켜주는 중.. 실제로 트랜잭션은 3분 정도..소요됩니다. (1개당 18초) 10분당 7분 놀고 있는 것. 처리할 수 있는만큼 계속 처리하게 하면 ( 비동기 / 카프카 .. ) 1개당 18초를 무한히 돌릴 수 있다. 유저는 18초 기다릴 걸 요청만 하고 끝나니까, 50ms 이내로 응답을 받을 수 잇음. ( 처리를 다 기다리는 게 아니라서 )우리의 목적 "대기열" 관리주체를 RDBMS -> REDIS 로 이관해보자! 콘서트별로 SortedSet 키를 구성하자! key : waiting-queue::{concert_id} ttl : XX // 자연말소시킬수도 있ㅇ므.. value : SortedSet { value : token_id, score : request_timestamp(정수) } zpopmin zrank -> 순위 (오름차순) zrevrank -> 내림차순 순위 ----> API Spec 도 바뀌어야 한다. 기존에는 토큰ID 만 보냄. 콘서트 ID 를 requestParam 으로 받아야함. ( PathVariable ) API Spec + Infra 변경1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- MongoDB, Flink, Cassandra => 시간잇으면 추가하기
## Redis에 대해서
- Redis 는 Key-Value 기반 NoSQL ( DB ) 이다.
- 원자성
- 싱글 스레드
- 레디스를 운영환경에서 쓸 때는, O(n) 이상의 행위는 최대한 지양해야 합니다.
- keys => 키가 100만개있으면..?! 레디스가 아무리 빨라도 n초동안 멈춤. ( 그거 하고 있을 테니 커맨드 수용 x )
- Key - value
- TTL : key - value 답게 "value" 단위로만 걸 수 잇음.
- **value 종류**
- strings
- sets
- lists
- sortedSets
- **SortedSet 의 { member , score } 특정 value 에 TTL 못건다!!!**
- hashSets
- Redis와 RDBMS차이
- REDIS => NoSQL => 목적 : "조회성능 향상"
- RDBMS => 조회성능에 한계가 있음.
=> 정규화 + 관계 테이블.. => JOIN ( 인덱스 파편화되는 문제로 이어짐 )
- 추가정보
- 이번에 레디스로 대기열 설계를 그릴 수 있다? 보고서 가능?
어지간한 백엔드 개발자 설계 면접 합격 가능. ( 대기열이 맛돌이 주제다.. )
- 예시
-
class QueeueService {
Token issue(User user, Long concertId) {
대기열 있어?
if (없으면) 대기열 생성
tokenRepository.get(user.id, concertId) <- 그냥 무지성 put 하면 갱신되니까.
// validation
new Token().save./
}
}
1
2
-
콘서트 오픈 -> 콘서트 다 팔릴 때까지 걸린 시간의 랭킹.
---> 예약 때마다 할 필요 ? x
---> 결제 때마다도 매번 스코어를 바꿔줘야할까? x
---> 결제 때마다
(1) 매진인지 체크
(2) 매진이라면, DB 의 공연 오픈시각과 현재시각을 비교한 값을 Score 로 넣어야함.
--> 결제마다 +1 씩함.
--> 매진되면 + 1000000 함
이커머스 회사에서 랭킹..
인기도란 무엇일까..?
- 주문 * 0.3
- 조회 * 0.1
- 좋아용 * 0.4
- 장바구니 * 0.2
1
2
3
4
- 자주쓰는 redis자료구조
-
Strings <- 기본 ( 캐시 에서 100% 활용 )
SortedSet <- Ranking
"우선순위 정렬" <- 어떤 걸 score 로 잡냐에 따라서 천차만별로 풀어낼 수 있음.
score = 요청 timestamp : 선착순
score = 갯수 : 오름차순/내림차순 랭킹
어제, 그제, 오늘 3일치의 스코어를 합산 : ZUNION ... 이런 명령어로 쉽게 합칠 수 있음.
HashSet ->
Category = 대략 1400~2000 개
HashSet {
"카테고리코드" : "카테고리이름",
...
..
}
Set <- 어디서든 만능 ( 중복 제거 )
이거 이상으로 안씀. ㅋ
Strings <- incr, decr 를 생각보다 쓸 대가 많음.
"원자성" 을 보장하고 "동시성 이슈" 없이 개수를 측정해야 할 때 사기캐
1
2
3
4
5
6
7
8
9
10
11
12
13
14
- 대기유저와 활성유저
- **대기유저 (Waiting Tokens)**
- SortedSets 자료구조 활용
```jsx
ZADD waiting-tokens 100 "user1"
ZADD waiting-tokens 200 "user2"
ZADD waiting-tokens 150 "user3"
ZPOPMIN waiting-tokens 2
// user1, user3
- member : 토큰 / score : 요청시각
- ZADD - 신규 대기 토큰 추가
- ZRANK - 내 토큰이 몇 등인지 확인
- ZRANGE / ZPOPMIN - 활성화 토큰 대상을 조회 or POP
**활성유저 (Active Tokens)**
- Sets 자료구조 활용
1
2
3
4
5
SADD active-tokens "user1"
SADD active-tokens "user2"
SCARD active-tokens
// 2
- key : 토큰
- SADD - 신규 활성 토큰 추가
- SCARD - 현재 활성 토큰 개수 조회
- SREM - 특정 활성 토큰 제거
**Active Tokens 전환 방식**
1. Active Tokens 에서 만료된 토큰의 수만큼 Waiting Tokens에서 전환
- 서비스를 이용할 수 있는 유저를 항상 **일정 수 이하로 유지**할 수 있다.
- 서비스를 이용하는 유저의 액션하는 속도에 따라 대기열의 전환시간이 불규칙하다.
2. N초마다 M개의 토큰을 Active Tokens 으로 전환
- 대기열 고객에게 서비스 진입 가능 시간을 대체로 보장할 수 있다.
- 서비스를 이용하는 유저의 수가 보장될 수 없다.Redis전용 ObjectMapper만들기
@Bean fun redisCacheConfiguration(): RedisCacheConfiguration { return RedisCacheConfiguration.defaultCacheConfig() .serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(StringRedisSerializer())) .serializeValuesWith( RedisSerializationContext.SerializationPair.fromSerializer( GenericJackson2JsonRedisSerializer(redisObjectMapper()) ) ) .entryTtl(Duration.ofDays(1)) } @Bean fun redisObjectMapper(): ObjectMapper { val objectMapper = ObjectMapper() objectMapper.registerModule(KotlinModule.Builder().build()) objectMapper.activateDefaultTyping( objectMapper.polymorphicTypeValidator, ObjectMapper.DefaultTyping.EVERYTHING, JsonTypeInfo.As.WRAPPER_OBJECT ) return objectMapper }